本文的内容主要是翻译文档Kaldi tutorial,这是第二部分。更多本系列文章请点击Kaldi文档解读。
目录
运行示例脚本(40分钟)
prerequisites
接下来我们要运行LDC的RM数据集,这个数据集是收费的。但是读者即使没有这个数据集,也建议不要跳过。读者可以找一个有数据的例子,比如mini_librispeech,作者给出的输出就是这个recipe的数据,这个数据是librispeech的一小部分数据,这样可以很快的跑外。读者也可以参考Kaldi简介,这里是中文的thchs30数据集,也是开源的。
首先我们进入egs/rm/s5,这是我们的主要工作目录。
数据准备
准备dict
我们首先需要配置是在单机还是在Oracle GridEngine集群上训练,这可以通过cmd.sh来配置。如果我们没有GridEngine(通常没有),那么需要把所有的queue.pl改成run.pl:
train_cmd="run.pl"
decode_cmd="run.pl"
接下来把RM数据集划分成训练集和测试集(假设RM数据集在/export/corpora5/LDC/LDC93S3A/rm_comp目录下):
./local/rm_data_prep.sh /export/corpora5/LDC/LDC93S3A/rm_comp
如果没有问题,那么它会输出”RM_data_prep succeeded”,否则请根据反馈解决问题。
运行后在当前目录会生成data目录,这个目录下有如下三类子目录:
- local 包括当前数据的dictionary
- train 训练数据
- test_* 不同的测试数据
下面我们简单的看一下这些数据,更详细的数据准备读者可以参考Data preparation。
我们首先看local目录:
cd local/dict
head lexicon.txt
head nonsilence_phones.txt
head silence_phones.txt
看过这些文件后读者对Kaldi数据准备的结果会有一些了解。这些文件并不都是Kaldi的C++程序直接处理,它们可能需要先用OpenFst的命令预先处理。
- lexicon.txt 发音词典
- *silence*.txt 说明哪些phone是silence,哪些是non-silence
接着我们进入train目录,查看如下命令的结果:
head text
head spk2gender
head spk2utt
head utt2spk
head wav.scp
-
text 这个文件可以看成一个map,key是utterance id,value是utterance的词序列(词之间用空格分开)。
-
spk2gender 说话人(speaker)id到性别的map。
-
spk2utt 某个说话人的所有utternace id
-
utt2spk 某个utterance的说话人,前面的spk2utt可以由这个文件生成(当然反过来也行)
-
wav.scp 这是Kaldi提取特征时真正用到的文件,这个文件的第一列是utterance id,第二列是扩展文件名(extended filename),扩展文件名可以是普通的文件路径,也可以是一些命令行的输出,更多扩展文件名的信息请参考这里。我们这里可以先把第二列当作录音文件的路径。
test_*目录的结构和train是一样的,只不过训练数据通常要大一些,我们可以比较一下:
wc train/text test_feb89/text
准备lang
接下来是创建lang目录。我们在s5目录下执行如下的命令:
./utils/prepare_lang.sh data/local/dict '!SIL' data/local/lang data/lang
这个命令有4个参数,第一个就是我们前面准备的dict(data/local/dict),第二个是告诉它OOV是哪个,第三个参数是临时目录用于保留中间的结果,第四个是输出目录。
下面我们介绍输出目录的内容。
首先是words.txt和phones.txt文件,这是OpenFst格式的符号表,它的作用是把字符串映射成整数(当然也可以反过来)。
再来看一下data/lang/phones目录下后者为.csl的文件。比如:
$ ll phones/*.csl
-rw-rw-r-- 1 lili lili 21 4月 24 17:14 phones/context_indep.csl
-rw-rw-r-- 1 lili lili 68 4月 24 17:14 phones/disambig.csl
-rw-rw-r-- 1 lili lili 1255 4月 24 17:14 phones/nonsilence.csl
-rw-rw-r-- 1 lili lili 2 4月 24 17:14 phones/optional_silence.csl
-rw-rw-r-- 1 lili lili 21 4月 24 17:14 phones/silence.csl
我们来看一个:
$ cat phones/nonsilence.csl
11:12:13:14:15:16:17:18:19:20:21:22:23:24:25:26:27:28:29:30:31:32:33:34:...省略
这是用冒号分割的non-silence的id列表,有一些命令行工具需要这类文件。
再看data/lang/phones.txt这个文件,这个文件包含所有的phone的符号表,也包括#1、#2等消歧符号,关于消歧符号读者可以参考Speech Recognition with Weighted Finite State Transducers,这篇论文经常也在网上被简称为hbka。我们也添加#0,这用于在语言模型中替代ε跳转,具体参考消歧符号。那么我们需要多少个消歧符号呢?通常它等于发音词典里最大的同音词(homophone)集合的大小。
L.fst是发音词典编译成的FST,我们可以用fstprint查看其内容:
fstprint --isymbols=data/lang/phones.txt --osymbols=data/lang/words.txt data/lang/L.fst | head
0 1 SIL <eps> 0.0100503359
0 2 <eps> <eps> 4.60517025
1 3 SIL_S !SIL
1 4 SPN_S <SPOKEN_NOISE>
1 5 SPN_S <UNK> -0.500775278
1 6 EY1_S A 2.04317451
1 7 AH0_S A 0.0833816081
1 8 EY1_B A''S
1 10 EY1_B A'BODY
1 15 EY1_B A'COURT
如果提示找不到fstprint命令,那很可能是没有source path.sh,我们可以在s5下执行:
. ./path.sh
准备G
接下来构建G.fst,使用如下命令:
local/rm_prepare_grammar.sh
注意:训练的时候是不需要G的,因为我们已经有正确的文本(transcript)了,只有在测试的时候才需要它。因此有些recipe把G.fst放到data/lang_test*下。
特征提取
run.sh里下面代码用于提取特征,我们需要设置变量featdir为存放特征的目录,它需要较大的可用空间。
export featdir=/my/disk/rm_mfccdir
mkdir $featdir
for x in test_mar87 test_oct87 test_feb89 test_oct89 test_feb91 test_sep92 train; do \
steps/make_mfcc.sh --nj 8 --cmd "run.pl" data/$x exp/make_mfcc/$x $featdir; \
steps/compute_cmvn_stats.sh data/$x exp/make_mfcc/$x $featdir; \
done
上面的代码会使用8个CPU来提取特征(--nj 8),我们可以根据机器的配置来设置合理的值。我们可以去exp/make_mfcc/train/make_mfcc.1.log查看执行命令的log。
在脚本steps/make_mfcc.sh里,我们可以看到它会调用”utils/split_scp.pl”脚本,读者可以猜测一下这个脚本的用途。运行下面的命令:
wc $featdir/raw_mfcc_train.1.scp
wc data/train/wav.scp
读者可以验证自己的猜想是否正确。
注:split_scp.pl的用途是把训练数据wav.scp拆分成很多的segment,每个segment包含一部分训练数据。
接下来看make_mfcc.sh的下面的代码:
$cmd JOB=1:$nj $logdir/make_mfcc_${name}.JOB.log \
extract-segments scp,p:$scp $logdir/segments.JOB ark:- \| \
compute-mfcc-feats $vtln_opts --verbose=2 --config=$mfcc_config ark:- ark:- \| \
copy-feats --compress=$compress $write_num_frames_opt ark:- \
ark,scp:$mfccdir/raw_mfcc_$name.JOB.ark,$mfccdir/raw_mfcc_$name.JOB.scp \
|| exit 1;
这段代码是对每一个segment都用compute-mfcc-feats来提取特征。--config指定提取MFCC特征的配置,通常是conf/mfcc.conf,我们可以在这个文件里设置。接下来的参数我们可以看到scp、ark,scp,这需要一些解释。但是在解释它们之前,我们先来看一下这些文件:
head data/train/wav.scp
head $featdir/raw_mfcc_train.1.scp
less $featdir/raw_mfcc_train.1.ark
注意:ark文件是二进制文件,用less等阅读文本文件的工具打开可能会把你的shell搞坏。为了查看二进制的ark文件的内容,我们可以用下面的命令copy-feats把它转换成文本格式再查看:
lili@lili-Precision-7720:~/codes/kaldi/egs/mini_librispeech/s5$ copy-feats ark:mfcc/raw_mfcc_train_clean_5.1.ark ark,t:- | head
copy-feats ark:mfcc/raw_mfcc_train_clean_5.1.ark ark,t:-
1088-134315-0000 [
72.40648 -19.36388 -44.40262 -10.19552 -21.3667 -3.640152 -16.40237 -1.930618 1.362324 -6.512866 -15.74331 4.008131 -1.47203
71.35578 -19.36388 -35.81796 2.004806 -16.43647 9.075225 -17.10159 -2.436302 12.22938 0.295476 -15.74331 -10.60617 -5.794979
70.8782 -20.64792 -40.96876 -4.943618 -14.89577 7.240695 -8.011686 4.137588 17.73151 -2.891407 -17.62235 -7.024161 -2.950933
70.4006 -18.72185 -31.81178 -3.921791 -19.826 -2.834986 -18.63988 5.148956 9.478315 -11.29319 -14.49062 -5.28222 3.678639
70.97372 -18.72185 -35.24565 2.004806 -24.44826 0.8198447 -16.68206 9.700111 5.745079 -7.092299 -12.97539 7.107261 11.62236
72.502 -17.4378 -42.11338 -7.191637 -20.28821 4.488903 -15.70314 4.137588 9.936827 2.323492 -9.037293 4.240391 11.24409
71.54682 -13.58566 -35.24565 -2.899964 -16.59054 6.782063 -3.233469 -0.4135665 1.362324 -13.03149 -11.00634 -0.520915 9.730999
72.59752 -11.65959 -36.96258 -4.534887 -24.44826 9.992489 -15.28361 -0.4135665 19.10705 5.269097 -2.473804 4.124261 10.48754
73.26614 -8.76799 -40.96876 -6.374176 -22.9074 2.654374 -15.70314 -2.436302 9.019805 -6.368007 -14.49062 -1.44995 2.543821
同样的数据可以用下面这个命令来查看:
lili@lili-Precision-7720:~/codes/kaldi/egs/mini_librispeech/s5$ copy-feats scp:mfcc/raw_mfcc_train_clean_5.1.scp ark,t:- | head
copy-feats scp:mfcc/raw_mfcc_train_clean_5.1.scp ark,t:-
1088-134315-0000 [
72.40648 -19.36388 -44.40262 -10.19552 -21.3667 -3.640152 -16.40237 -1.930618 1.362324 -6.512866 -15.74331 4.008131 -1.47203
71.35578 -19.36388 -35.81796 2.004806 -16.43647 9.075225 -17.10159 -2.436302 12.22938 0.295476 -15.74331 -10.60617 -5.794979
70.8782 -20.64792 -40.96876 -4.943618 -14.89577 7.240695 -8.011686 4.137588 17.73151 -2.891407 -17.62235 -7.024161 -2.950933
70.4006 -18.72185 -31.81178 -3.921791 -19.826 -2.834986 -18.63988 5.148956 9.478315 -11.29319 -14.49062 -5.28222 3.678639
70.97372 -18.72185 -35.24565 2.004806 -24.44826 0.8198447 -16.68206 9.700111 5.745079 -7.092299 -12.97539 7.107261 11.62236
72.502 -17.4378 -42.11338 -7.191637 -20.28821 4.488903 -15.70314 4.137588 9.936827 2.323492 -9.037293 4.240391 11.24409
71.54682 -13.58566 -35.24565 -2.899964 -16.59054 6.782063 -3.233469 -0.4135665 1.362324 -13.03149 -11.00634 -0.520915 9.730999
72.59752 -11.65959 -36.96258 -4.534887 -24.44826 9.992489 -15.28361 -0.4135665 19.10705 5.269097 -2.473804 4.124261 10.48754
73.26614 -8.76799 -40.96876 -6.374176 -22.9074 2.654374 -15.70314 -2.436302 9.019805 -6.368007 -14.49062 -1.44995 2.543821
为什么呢?因为这个scp文件可以认为是对应的ark的”索引”文件:
lili@lili-Precision-7720:~/codes/kaldi/egs/mini_librispeech/s5$ head mfcc/raw_mfcc_train_clean_5.1.scp
1088-134315-0000 /home/lili/codes/kaldi/egs/mini_librispeech/s5/mfcc/raw_mfcc_train_clean_5.1.ark:17
1088-134315-0001 /home/lili/codes/kaldi/egs/mini_librispeech/s5/mfcc/raw_mfcc_train_clean_5.1.ark:20985
1088-134315-0002 /home/lili/codes/kaldi/egs/mini_librispeech/s5/mfcc/raw_mfcc_train_clean_5.1.ark:40913
1088-134315-0003 /home/lili/codes/kaldi/egs/mini_librispeech/s5/mfcc/raw_mfcc_train_clean_5.1.ark:57396
1088-134315-0004 /home/lili/codes/kaldi/egs/mini_librispeech/s5/mfcc/raw_mfcc_train_clean_5.1.ark:72826
1088-134315-0005 /home/lili/codes/kaldi/egs/mini_librispeech/s5/mfcc/raw_mfcc_train_clean_5.1.ark:90427
1088-134315-0006 /home/lili/codes/kaldi/egs/mini_librispeech/s5/mfcc/raw_mfcc_train_clean_5.1.ark:106234
1088-134315-0007 /home/lili/codes/kaldi/egs/mini_librispeech/s5/mfcc/raw_mfcc_train_clean_5.1.ark:126097
1088-134315-0008 /home/lili/codes/kaldi/egs/mini_librispeech/s5/mfcc/raw_mfcc_train_clean_5.1.ark:144530
1088-134315-0009 /home/lili/codes/kaldi/egs/mini_librispeech/s5/mfcc/raw_mfcc_train_clean_5.1.ark:164471
ark文件就是这个Segment的所有的录音的MFCC特征,比如第一个是utterance id为1088-134315-0000的特征。但是这样的ark文件要查找起来就很麻烦,比如我们想找到1088-134315-0009,那么就得顺序的读取ark文件。而通过scp文件,我们可以马上就定位到它在ark文件的开始位置是164471。
因此我们可以使用下面的命令查看这个segment的第十个录音的特征:
lili@lili-Precision-7720:~/codes/kaldi/egs/mini_librispeech/s5$ head -10 mfcc/raw_mfcc_train_clean_5.1.scp | tail -1 | copy-feats scp:- ark,t:- | head
1088-134315-0009 [
55.72003 -6.679877 -15.74406 -7.949226 -8.96592 -16.10855 -15.05192 1.05929 5.661386 5.846256 -9.279142 3.467848 -5.840376
54.65408 -13.493 -22.21632 -19.13253 -12.44794 -15.5161 -24.69204 -8.764364 -7.518635 -3.32707 -8.922056 10.65484 -1.303337
54.65408 -13.493 -18.95379 -9.942627 -11.79506 -4.852167 -13.63782 -19.48893 -4.859941 -4.817736 -4.994106 1.496331 4.93276
55.0094 -9.263911 -11.697 -7.224352 -12.66556 -5.918561 -21.60785 -13.24071 -1.820446 -3.441737 -9.874287 5.671308 -10.00711
我们来拆解上面的命令。head -10找到前十行,然后tail -1提取最后一行也就是”1088-134315-0009 /home/lili/codes/kaldi/egs/mini_librispeech/s5/mfcc/raw_mfcc_train_clean_5.1.ark:164471”。然后把它作为copy-feats的输入,这样它就会读取utterance 1088-134315-0009的特征。
注意copy-feats的输入是”scp:-“,”-“的意思是从标准输入(来自管道)读取scp文件,它等价于读取一个scp文件,这个scp文件只有一行:
1088-134315-0009 /home/lili/codes/kaldi/egs/mini_librispeech/s5/mfcc/raw_mfcc_train_clean_5.1.ark:164471
接下来我们来介绍script(scp)和archive(ark)文件,注意这里的script和脚本编程没有任何关系,我们简单的把它看成”索引”文件就可以了。我们来看一下copy-feats.cc的代码:
lili@lili-Precision-7720:~/codes/kaldi/egs/mini_librispeech/s5$ tail -30 ../../../src/featbin/copy-feats.cc
KALDI_LOG << "Copied " << num_done << " feature matrices.";
return (num_done != 0 ? 0 : 1);
} else {
KALDI_ASSERT(!compress && "Compression not yet supported for single files");
if (!num_frames_wspecifier.empty())
KALDI_ERR << "--write-num-frames option not supported when writing/reading "
<< "single files.";
std::string feat_rxfilename = po.GetArg(1), feat_wxfilename = po.GetArg(2);
Matrix<BaseFloat> feat_matrix;
if (htk_in) {
Input ki(feat_rxfilename); // Doesn't look for read binary header \0B, because
// no bool* pointer supplied.
HtkHeader header; // we discard this info.
ReadHtk(ki.Stream(), &feat_matrix, &header);
} else if (sphinx_in) {
KALDI_ERR << "For single files, sphinx input is not yet supported.";
} else {
ReadKaldiObject(feat_rxfilename, &feat_matrix);
}
WriteKaldiObject(feat_matrix, feat_wxfilename, binary);
KALDI_LOG << "Copied features from " << PrintableRxfilename(feat_rxfilename)
<< " to " << PrintableWxfilename(feat_wxfilename);
}
} catch(const std::exception &e) {
std::cerr << e.what();
return -1;
}
}
上面的代码看起来不少,但其实真正干活的就三行(有三个分支,分别读取HTK、Sphinx和Kaldi格式的数据):
Matrix<BaseFloat> feat_matrix;
ReadKaldiObject(feat_rxfilename, &feat_matrix);
WriteKaldiObject(feat_matrix, feat_wxfilename, binary);
如果读者数学OpenFst的StateIterator,那么会发现Kaldi的style是非常类似的。
理解scp和ark文件的关键是Table的概念。Table可以看成一个List,List的每个原始都是一个Key和一个Value。比如Value是浮点数的矩阵的时候(Matrix
BaseFloatMatrixWriter
RandomAccessBaseFloatMatrixReader
SequentialBaseFloatMatrixReader
这三个类其实是TableWriter等模板类的typedef:
typedef TableWriter<KaldiObjectHolder<Matrix<BaseFloat> > >
BaseFloatMatrixWriter;
typedef SequentialTableReader<KaldiObjectHolder<Matrix<BaseFloat> > >
SequentialBaseFloatMatrixReader;
typedef RandomAccessTableReader<KaldiObjectHolder<Matrix<BaseFloat> > >
RandomAccessBaseFloatMatrixReader;
我们可以先忽略KaldiObjectHolder,把它看成TableWriter<Matrix
- scp 文件是文本文件,第一列是id;第二列是扩展文件名(extended filename),作用是告诉Kaldi去哪里读取文件。
- ark 可以是文本格式的也可以是二进制格式的(默认是二进制,我们可以在输入或者输出加一个t,比如”ark,t”)。对于文本格式,每行是一个数据,具体为key+空格+数据本身
下面是关于scp和ark文件的一些要点:
- 用于说明(specify)怎么读取文件的字符串叫做rspecifier(read specifier的意思),比如”ark:gunzip -c my/dir/foo.ark.gz|”
- 它的意思是输入是一个ark文件,首先通过gunzip -c解压foo.ark.gz然后把解压的结果重定向给ark的读取程序(比如SequentialTableReader)。注意 gunzip 要带-c,否则gunzip会把解压后的内容覆盖原来的gz文件而且也不会把输出写到标准输出(stdout)中。
- 用于说明怎么写文件的字符串叫做wspecifier,比如”ark,t:foo.ark”
- 它的意思是输出为ark文件,并且是文本格式的,到foo.ark文件
-
ark文件可以concat起来(因为Table只是一个List)
-
scp和ark文件都既可以顺序的读取也可以随机的读取
-
Kaldi(scp和ark文件)并不知道存储的数据是什么类型的,也就是说Kaldi并不像Protobuf这类序列化工具把数据的schema也保存下来。使用的人(KaldiObjectHolder)必须知道数据的类型
-
ark和scp文件只能包含一种Value类型(key只能是string),不能第一个元素是一种类型而第二个元素是第二种类型
-
ark文件的随机读取是非常低效的,为了随机读取只能把已经读取的数据都保存到Cache里(否则为了找一个key把整个文件都扫一遍更慢)
- 为了高效的随机读取,我们在输出时可以指定”ark,scp”
- 这样它会产生scp和ark两个文件,而且scp是ark的索引,就像前面我们看到的例子。当然scp也不一定是某个ark的索引,比如wav.scp它只是指定utterance id对应的文件。
- 如果我们需要随机的读取,并且ark文件是按照id排序的,再并且我们访问数据是按照id顺序的(可以跳过),那么我们可以指定rspecifier为”ark,s,cs:-“
比如我们的ark是”1:aaaaa 3:hi 5:dd”,也就是有3个数据,因为已经按照id排序,而且我们虽然是随机访问,但是保证顺序访问,因此Kaldi不需要Cache。读者可能会问实际什么情况会用到这种方式。
比如我们有两个文件,a.ark:
2:bbbb 4:cccc 5:dddd 7:eeeee
和b.ark:
1:cccc 3:xxxx 8:ffff 9:abcd
它们都已经按照id排好序了。现在我们想合并它们,那么我们的伪代码可能如下:
SequentialTableReader r1("ark:a.ark");
RandomAccessTableReader r2("ark,s,cs:b.ark");
for(; !r1.Done(); r1.Next()) {
std::string k1 = r1.Key();
if(r2.HasKey(k1)) {
//merge
}
比如现在调用r2.HasKey(“2”),那么扫描1:cccc和3:xxxx就可以停下来并且返回false了。因为b.ark是排好序的,所以顺序扫描要么找到2,要么找到第一个比2大的就可以判断它不存在。这就是”ark,s,cs”里s的作用。接着调用r2.HasKey(“4”),因为”ark,s,cs”里的cs,所以我们知道第二次调用HasKey()的参数一定比第一次大,所以我们接着从上次扫描b.ark的位置(3:xxxx)寻找4。但是如果假设a.ark没有排序,它的内容为:
4:cccc 2:bbbb 5:dddd 7:eeeee
也就是第一次调用r2.HasKey(“4”),第二次调用r2.HasKey(“2”),这样我们要么每次都对b.ark的从头扫描一遍(直到找到大于等于key的位置),要么我们把以前读过的内容cache到内存里。这两种方法都不好,因为前者速度太慢而后者会消耗大量内存。
为了检验是否理解,读者可以用下面的命令测试一下,确保能够理解这个命令是在做什么。
head -1 $featdir/raw_mfcc_train.1.scp | copy-feats scp:- ark:- | copy-feats ark:- ark,t:- | head
注:它其实等价于更加简单的:
head -1 $featdir/raw_mfcc_train.1.scp | copy-feats scp:- ark,t:- | head
最后我们把所有的测试数据集合并成一个测试数据集,这样比较方便。
utils/combine_data.sh data/test data/test_{mar87,oct87,feb89,oct89,feb91,sep92}
steps/compute_cmvn_stats.sh data/test exp/make_mfcc/test $featdir
接下来我们创建一个较小的训练集train.1k,它会抽取每个说话人的1000个utterance。
utils/subset_data_dir.sh data/train 1000 data/train.1k
Monophone模型训练
下一步是训练Monophone的模型。因为Kaldi的脚本通常使用相对路径,实验的临时结果一般放在s5/exp下。如果你的kaldi的空间不够(比如装在了HOME下),那么可以使用符号链接把exp目录链接到一个有足够空间的地方。运行下面的脚本进行训练:
nohup steps/train_mono.sh --nj 4 --cmd "$train_cmd" data/train.1k data/lang exp/mono &
这个脚本在后台运行,我们可以用tail看动态的日志:
tail -f nohup.out
通过nohup命令可以让程序在后台执行,即使我们退出terminal也是这样。当然更好的办法是使用screen或者tmux这样的工具,读者可以自行搜索这些工具的用法。标准输出(屏幕)的内容是比较少的,大部分信息都保存在exp/mono下。
在程序执行的时候我们抽空来看一下data/lang/topo文件,这个文件在运行上面的脚本后很快就会被创建。有一个phone的HMM的拓扑(topo)结构和别的是不同的,请找出来,因为这里都是id,读者可以参考phones.txt把它变成phone的符号。因为我没有RM数据,我这里是使用mini-librispeech的结果,所以和官方文档有一些区别:
<Topology>
<TopologyEntry>
<ForPhones>
11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346</ForPhones>
<State> 0 <PdfClass> 0 <Transition> 0 0.75 <Transition> 1 0.25 </State>
<State> 1 <PdfClass> 1 <Transition> 1 0.75 <Transition> 2 0.25 </State>
<State> 2 <PdfClass> 2 <Transition> 2 0.75 <Transition> 3 0.25 </State>
<State> 3 </State>
</TopologyEntry>
<TopologyEntry>
<ForPhones>
1 2 3 4 5 6 7 8 9 10
</ForPhones>
<State> 0 <PdfClass> 0 <Transition> 0 0.25 <Transition> 1 0.25 <Transition> 2 0.25 <Transition> 3 0.25 </State>
<State> 1 <PdfClass> 1 <Transition> 1 0.25 <Transition> 2 0.25 <Transition> 3 0.25 <Transition> 4 0.25 </State>
<State> 2 <PdfClass> 2 <Transition> 1 0.25 <Transition> 2 0.25 <Transition> 3 0.25 <Transition> 4 0.25 </State>
<State> 3 <PdfClass> 3 <Transition> 1 0.25 <Transition> 2 0.25 <Transition> 3 0.25 <Transition> 4 0.25 </State>
<State> 4 <PdfClass> 4 <Transition> 4 0.75 <Transition> 5 0.25 </State>
<State> 5 </State>
</TopologyEntry>
从上面可以看成,大部分phone都是3状态的HMM,而id从1到10的phone是5状态的HMM(RM里例子应该只有一个5状态的HMM)。我们通过phones.txt可以发现这些phone的符号:
lili@lili-Precision-7720:~/codes/kaldi/egs/mini_librispeech/s5$ head -15 data/lang/phones.txt
<eps> 0
SIL 1
SIL_B 2
SIL_E 3
SIL_I 4
SIL_S 5
SPN 6
SPN_B 7
SPN_E 8
SPN_I 9
SPN_S 10
AA_B 11
AA_E 12
AA_I 13
AA_S 14
我们发现1-10都是silence和spoken noise,也就是非”真实”的phone,我们用5状态的HMM来建模;而剩下的从11开始的都是”真实”的phone,我们使用3状态的HMM。
这里的规定是:最后一个
<State> 0 <PdfClass> 0 <Transition> 0 0.75 <Transition> 1 0.25 </State>
<State> 1 <PdfClass> 1 <Transition> 1 0.75 <Transition> 2 0.25 </State>
<State> 2 <PdfClass> 2 <Transition> 2 0.75 <Transition> 3 0.25 </State>
<State> 3 </State>
</TopologyEntry>
它说明3是终止状态,0是第一个状态,它跳到自己的概率是0.75,跳到1的概率是0.25;其它的状态的跳转概率也是类似的。注意:这里的跳转概率是初始的值,我们把0.75改成0.7也问题不大。因为它会根据数据训练出最优的跳转概率。但是不能改成0,概率为0的初始跳转训练后也会是0。
输入:
gmm-copy --binary=false exp/mono/0.mdl - | less
exp/mono/0.mdl是我们初始的模型,我们发现最开始的内容是复制的topo文件,也就是模型会把topo拷贝一份进去。在下面就是模型的参数,包括状态的跳转概率,以及每个状态的GMM参数,比如下面就是GMM的均值和协方差矩阵(对角的):
<DiagGMM>
<GCONSTS> [ -89.8917 ]
<WEIGHTS> [ 1 ]
<MEANS_INVVARS> [
-0.002237871 -0.0004438629 0.001633558 0.001939811 -0.001665733 0.002383299 -0.001329791 0.004471197 -0.00084000
27 0.001532784 -0.000466452 0.001277358 -0.003607793 -0.000248232 -0.0001158273 -0.0001779331 0.0004042523 4.14222
8e-05 -0.000156252 -0.0001166775 0.0002564711 -3.099937e-06 -0.0005655897 7.407984e-05 0.0001862098 -0.0002665676
5.614738e-05 0.0001465053 0.0002796003 -0.0002281889 0.0001982365 4.201251e-05 -0.0001849387 -0.0002621952 1.86133
5e-06 -0.000158677 5.518926e-05 6.271415e-06 0.0001973529 ]
<INV_VARS> [
0.007917241 0.003136008 0.005371662 0.004017648 0.004785415 0.005306521 0.005494438 0.005061673 0.006123316 0.00
626732 0.006645105 0.007697346 0.01124685 0.1453676 0.05953241 0.09568093 0.0740561 0.07184018 0.0717129 0.0789019
3 0.070612 0.08550961 0.08309221 0.0838424 0.1018051 0.1408613 0.8389055 0.4071355 0.5535619 0.4509267 0.4132705 0
.3887203 0.438167 0.3896935 0.4683907 0.4553423 0.448575 0.545741 0.7389754 ]
</DiagGMM>
.mdl包含两个对象:一个是TransitionModel对象,它包含了前面的topo(对于的类是HmmTopology)的定义;另一个是模型,比如AmGmm(注:mini_librispeech用的是DiagGMM)。这样的对象和Table文件(scp和ark)是不同的,它是没有key的。这些对象的输出都是特定的类代码实现的,没有任何格式的要求,一般也都支持二进制的输出和文本的输出,我们一般通过选项--binary来设置(默认是true)。而Table文件是统一的key-value格式(虽然不同的模板参数具体的value格式不一样),也统一通过specifier里的t来指定文本格式(默认没有t就是是二进制)。
读者可以看看模型文件里都有些什么内容,我们这里不会详细介绍,请参考HMM topology and transition modeling了解更多细节。
但是这里要澄清一个重要的概念:在Kaldi里pdf是一个从零卡开始的整数id,它们没有名字,这是和HTK不同的。.mdl文件里并没有足够的信息把上下文相关的phone映射成pdf-id。这个映射关系是存放在决策树里的,可以用如下命令查看:
copy-tree --binary=false exp/mono/tree - | less
注意:monophone的决策树是很trivial的,每个phone就是一棵树,而且这棵树只有一个根节点。虽然tree文件的格式最早设计不是给人看的,但是有多用户都像看这个文件的内容,所以我们还是解释一下其内容。不感兴趣的读者可以跳过解释tree文件内容的部分(作者建议还是不要跳过,在后面的tree internal还会再详细解释,这里先熟悉一下,不能完全看到也没关系)。
我们参考下面的tree来阅读文档,这个tree来自Decision tree internals。
s3# copy-tree --binary=false exp/tri1/tree - 2>/dev/null | head -100
ContextDependency 3 1 ToPdf SE 1 [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 \
26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59\
60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 9\
3 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 1\
20 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 14\
5 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170\
171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 \
196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 ]
{ SE 1 [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34\
35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 6\
8 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 10\
1 102 103 104 105 106 107 108 109 110 111 ]
{ SE 1 [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34\
35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 ]
{ SE 1 [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ]
{ SE 1 [ 1 2 3 ]
{ TE -1 5 ( CE 0 CE 1 CE 2 CE 3 CE 4 )
SE -1 [ 0 ]
{ SE 2 [ 220 221 222 223 ]
{ SE 0 [ 104 105 106 107 112 113 114 115 172 173 174 175 208 209 210 211 212 213 214 215 264 265 266 \
267 280 281 282 283 284 285 286 287 ]
{ CE 5 CE 696 }
SE 2 [ 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 132 \
133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 248 249 250 251 252 253 254 255 256 257 2\
58 259 260 261 262 263 268 269 270 271 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 30\
3 ]
ContextDependency说明这棵树是triphone的决策树(monophone是特殊的triphone),3表示加上下文共有3个phone,1表示”中心”的phone的下标(下标是0、1、2,因此1就是中间的那个)。如果是monophone的话”3 1”就会变成”1 0”。ToPdf后面就是一个多态的(polymorphic)的EventMap对象。EventMap的Key是<Key,Value>pair的list,这个list描述了triphone的三个phone,以及它是HMM的哪个状态。比如某个EventMap的key描述的是b-a+t的第二个HMM状态(具体怎么描述我们暂且略过)。EventMap的Value是pdf-id。那么通过这个对象,给定一个triphone和哪个状态,我们就能找到对于的pdf-id。
逻辑上EventMap就是上面描述的,把triphone映射出pdf-id。它怎么映射出来的呢?这就是决策树的决策过程,我们通过下图简单的回顾一些phone决策树的概念。更详细的介绍请参考基于HMM的语音识别(三)。
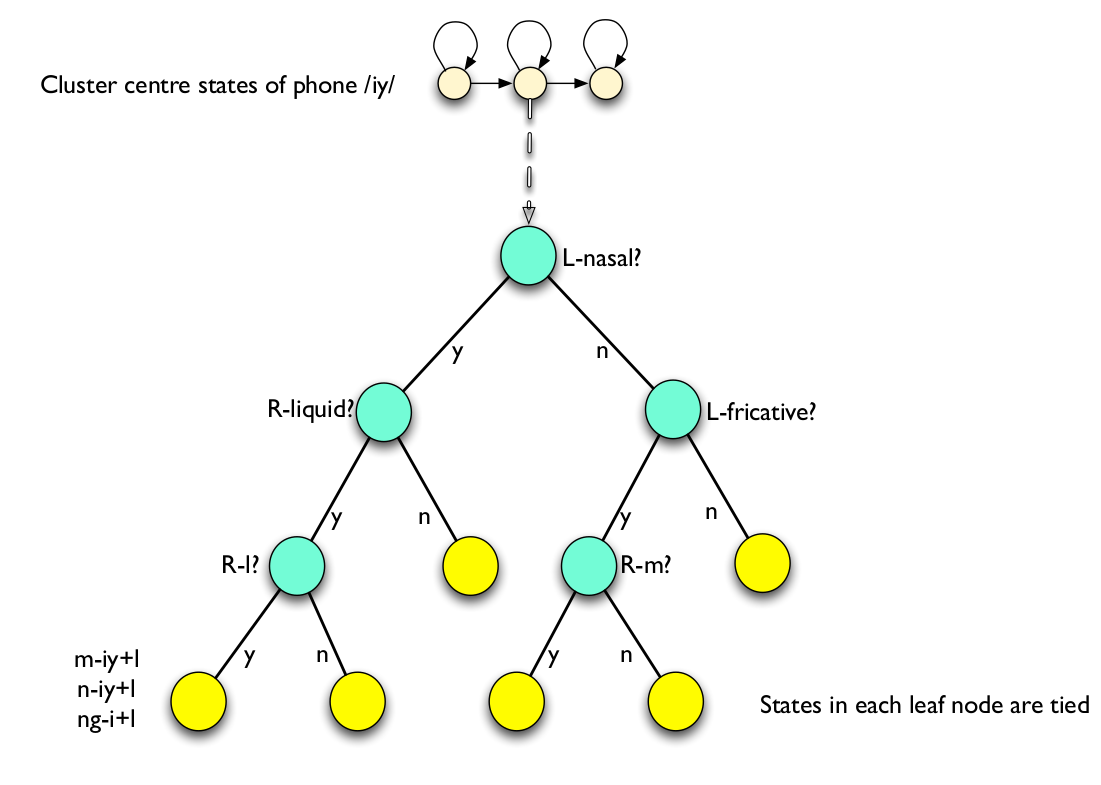 图:语音决策树示例
图:语音决策树示例
比如给定triphone n-iy+l的第二个状态,我们怎么找到叶子节点呢?我们是通过一些问题从根节点一直往下走到叶子节点。比如n-iy+l的例子,我们首先找到它的第二个状态所在的决策树的树根(这里的例子是把中心phone是iy的所有第二个状态都放到一棵树下),然后问第一个问题:”左边(n)是鼻音(nasal)吗?”,答案是肯定的,这里左边的n是个鼻音,因此往左边走。….。最终走到叶子节点,从而找到pdf-id。
虽然Kaldi的决策树和上面的不完全一样,比如决策树的问题是自动聚类出来的(而不是语言学家总结出来的),比如一个triphone的不同状态(比如n-iy+l的三个HMM状态)都可能放到一棵决策树下面,但是基本的原理还是一样的。
原理清楚了,那怎么把这棵树在内存中表示呢?首先我们看叶子节点,叶子节点使用ConstantEventMap(前面命令行的输出简写为CE)。我们可以在上面看到类似”CE 0”,那么就可以知道这个叶子对应的pdf-id是0。
接下来我们来看SplitEventMap,这就是我们理解的决策树,根据一个问题分为两个子树,它的定义为:
SplitEventMap := "SE" <key-to-split-on> "[" yes-value-list "]" "{" EventMap EventMap "}"
首先是字符串”SE”,然后是”问题”。注意Kaldi的决策树问题和前面我们描述的有些不同。前面我们说的问题是”这个triphone的左边是不是一个鼻音?”,而Kaldi的问题都是”某个key的value是不是属于集合L”。这看起来似乎很不一样,似乎Kaldi的问题太简单,都是一种类型,但是Kaldi的问题可能(这里只是可能,因为这些问题也是聚类学习出来的)等价于上面的问题。比如集合L就是所有鼻音的集合,而Key是问一个triphone的左边的音素,那么这个问题就等价于”这个triphone的左边是不是一个鼻音?”。因此用Kaldi来描述就是:
SE 0 [3 4 5 6] {EventMap EventMap}
假设鼻音的集合是${3,4,5,6}$,0代表问triphone的第一个音素(也就是中心音素的左边),大括号里面是两个子树(EventMap)。那么这个问题就等价于问”这个triphone的左边是不是一个鼻音?”
接着我们介绍TableEventMap,它的定义是:
TableEventMap := "TE" <key-to-split-on> <table-size> "(" EventMapList ")"
TableEventMap并不是真的决策树,或者我们可以认为是Table,它没有问题。比如:
TE -1 5 ( CE 0 CE 1 CE 2 CE 3 CE 4 )
它的意思是,这个节点不问问题,只是根据triphone的状态(这里是silence,HMM有5个状态)来查表决定怎么继续分裂。如果是triphone的第一个状态,那么就是EventMapList的第一个元素。这里很简单,第一个元素已经是叶子了(CE 0),但是也可能是SplitEventMap等更加复杂的树。
我们再来总结一下,普通的决策树的一个节点,要么是叶子节点直接得到pdf-id(CE),要么是问一个问题分成两个分支(SE)。理论上有这两种节点就可以实现任何决策树了,那TE又是干什么用的呢?
但是TE不问问题,它更像一个指针,只是根据Key把我们引导到对应的子树下面,或者说它的问题不是一个yes-no的问题,而是一个多项的问题。比如上面的例子,你可以理解为问题是”这是triphone的HMM的第几个状态”,显然这个问题有5种(或者3种)可能的答案。如果是第一个状态,那么就进入第一个子树;如果是第三个状态就进入第三个子树。
当然上面的逻辑也可以用SE实现,但这样就很冗余了,我们可能先问:”你是不是triphone的123个状态中的一个?”,如果是的话再问”你是不是triphone的12个状态的一个”,如果不是就知道它是第3个状态,如果是的话还要问题”你是不是第一个状态”。而使用TE就很简单,因为它可以看成多叉树而不是二叉树。
接下来我们看一下exp/mono/ali.1.gz,这个文件需要运行一段时间才有(因此如果你刚开始monophone的训练,可能还没有生成,那么就得等一下)。
copy-int-vector "ark:gunzip -c exp/mono/ali.1.gz|" ark,t:- | head -n 2
我们先来读一下这个命令,copy-int-vector就是复制int的向量,因此我们可以猜测出ali.1.gz的每一个对象就是一个int的向量。它的rspecifier是说明输入是一个ark文件,这个文件是gzip压缩的,因此使用gunzip -c 把它解压到标准输出上然后用管道作为copy-int-vector的输入,输出是”ark,t”,最后打印前两行。文件很长,我们这里显示部分内容:
copy-int-vector 'ark:gunzip -c exp/mono/ali.1.gz|' ark,t:-
1088-134315-0002 2 8 5 5 5 5 5 5 5 18 17 1838 1840 1839 1839 1839 1839 1839 1839 1839 1842 1841 1244 1243 1246 1248 806 805 805 805 808 807 810 1250 1252 1254 1253 1802 1801 1801 1801 1804 1803 1803 1803 1803 1803 1803 1806 1850 1849 1852 1854 1853 1853 1010 1009 1012 1014 1013 1013 1013 1013 1013 1013 1013 1013 1013 1013 764 763 763 766 768 767 416 415 415 418 417 417 417 420 1766 1765 1765 1765 1768 1770 1769 1346 1348 1350 1466 1465 1465 1468 1467 1470 1469 1106 1105 1108 1107 1107 1110 1109 1109 1109 1109 1826 1825 1825 1825 1825 1825 1825 1828 1827 1830 1829 410 412 414 1514 1516 1515 1515 1518 1517 1826 1825 1825 1825 1825 1825 1825 1828
第一列是utterance id,后面就是这个int向量。
所谓的对齐(alignment),其实就是要知道每一个时刻(frame)HMM的状态是什么,因此这个向量的长度就等于语音的帧数。读者可能猜测这里的整数是pdf-id,恭喜你!能这样思考说明是读懂了前面的内容,但是很可惜还是猜错了。这里的id是所谓的transition-id,其实跟pdf-id很接近了。我们现在可以大致认为它就是pdf-id,当然实际它比pdf-id还要更细粒度一点,比如某个时刻它所在的状态不管下一个状态是什么,按理应该都是一个pdf-id(因为HMM的发射概率只取决于当前状态而跟前一个状态无关),但是Kaldi的transition-id可以(但也不一定要)区分上面的情况,从而让这两种情况有不同的pdf-id(GMM)。
如果你想看看transition-id都长啥样,可以用下面的命令:
show-transitions data/lang/phones.txt exp/mono/0.mdl
它的输出类似,这是一个transtion-id:
Transition-state 93: phone = AA2_I hmm-state = 0 pdf = 10
Transition-id = 265 p = 0.75 [self-loop]
Transition-id = 266 p = 0.25 [0 -> 1]
我们这样来解读它:transition-state是93,transition-state可以认为是三元组(phone, hmm-state, pdf-id),因此这里是AA2_I的第一个状态,pdf-id是10。下面两行表示Transition-id,也就是topo文件里定义的,我们暂时不用管这个id。前面我们说了,Kaldi的pdf-id还可能与下一个状态有关,比如这里第一行是自跳转(下一个状态是自己)而第二行则是跳到下一个状态。
如果模型还有对于的occs文件,把它作为参数会得到更详细的信息,我们可以对比一下:
show-transitions data/lang/phones.txt exp/mono/40.mdl
Transition-state 1: phone = SIL hmm-state = 0 pdf = 0
Transition-id = 1 p = 0.932294 [self-loop]
Transition-id = 2 p = 0.0477094 [0 -> 1]
Transition-id = 3 p = 0.01 [0 -> 2]
Transition-id = 4 p = 0.01 [0 -> 3]
Transition-state 2: phone = SIL hmm-state = 1 pdf = 1
Transition-id = 5 p = 0.908964 [self-loop]
Transition-id = 6 p = 0.01 [1 -> 2]
Transition-id = 7 p = 0.01 [1 -> 3]
Transition-id = 8 p = 0.0710425 [1 -> 4]
show-transitions data/lang/phones.txt exp/mono/40.mdl exp/mono/40.occs
Transition-state 1: phone = SIL hmm-state = 0 pdf = 0
Transition-id = 1 p = 0.932294 count of pdf = 40180 [self-loop]
Transition-id = 2 p = 0.0477094 count of pdf = 40180 [0 -> 1]
Transition-id = 3 p = 0.01 count of pdf = 40180 [0 -> 2]
Transition-id = 4 p = 0.01 count of pdf = 40180 [0 -> 3]
Transition-state 2: phone = SIL hmm-state = 1 pdf = 1
Transition-id = 5 p = 0.908964 count of pdf = 30523 [self-loop]
Transition-id = 6 p = 0.01 count of pdf = 30523 [1 -> 2]
Transition-id = 7 p = 0.01 count of pdf = 30523 [1 -> 3]
Transition-id = 8 p = 0.0710425 count of pdf = 30523 [1 -> 4]
对比我们可以发现,加入occs文件后,还会多输出训练时pdf的计数,也就是状态占有概率,也就是Viterbi对齐后有多少个时刻的状态是这个transition-id,参考这里。
有了这些信息后,我们可以把ali里的transition-id变成phone等更加可读的内容,这可以使用更加适合的show-alignments(而不是简单的copy-int-vector)来查看:
show-alignments data/lang/phones.txt exp/mono/0.mdl "ark:gunzip -c exp/mono/ali.1.gz |" | less
运行后除了输出每一帧的transition-id,下面还会有对应的phone:
1088-134315-0002 SIL T_B IH0_E D_B IH0_I S_I T_I ER1_I B_E AH0_S R_B IY0_I L_I EY1_I SH_I AH0_I N_I SH_I IH2_I P_E W_B IH1_I CH_E AY1_S HH_B AE1_I V_E AO1_B L_I W_I IY0_I Z_E
这样我们就能知道每一帧对应的phone是什么了。
关于HMM topo、transition-id、transition模型相关的更多内容,请参考HMM topology and transition modeling。
接下来我们看一些训练过程中的输出:
grep Overall exp/mono/log/acc.{?,??}.{?,??}.log
它的输出类似于:
exp/mono/log/acc.39.2.log:LOG (gmm-acc-stats-ali[5.4.232-532f3]:main():gmm-acc-stats-ali.cc:115) Overall avg like per frame (Gaussian only) = -97.275 over 76910 frames.
exp/mono/log/acc.39.3.log:LOG (gmm-acc-stats-ali[5.4.232-532f3]:main():gmm-acc-stats-ali.cc:115) Overall avg like per frame (Gaussian only) = -98.7086 over 77414 frames.
exp/mono/log/acc.39.4.log:LOG (gmm-acc-stats-ali[5.4.232-532f3]:main():gmm-acc-stats-ali.cc:115) Overall avg like per frame (Gaussian only) = -96.8944 over 94493 frames.
exp/mono/log/acc.39.5.log:LOG (gmm-acc-stats-ali[5.4.232-532f3]:main():gmm-acc-stats-ali.cc:115) Overall avg like per frame (Gaussian only) = -100.415 over 92659 frames.
我们可以看到似然(likelihood)越来越大。接着看一下exp/mono/log/update.*.log:
lili@lili-Precision-7720:~/codes/kaldi/egs/mini_librispeech/s5$ cat exp/mono/log/update.1.log
# gmm-est --write-occs=exp/mono/2.occs --mix-up=127 --power=0.25 exp/mono/1.mdl "gmm-sum-accs - exp/mono/1.*.acc|" exp/mono/2.mdl
# Started at Wed Apr 24 14:38:14 CST 2019
#
gmm-est --write-occs=exp/mono/2.occs --mix-up=127 --power=0.25 exp/mono/1.mdl 'gmm-sum-accs - exp/mono/1.*.acc|' exp/mono/2.mdl
gmm-sum-accs - exp/mono/1.1.acc exp/mono/1.2.acc exp/mono/1.3.acc exp/mono/1.4.acc exp/mono/1.5.acc
LOG (gmm-sum-accs[5.4.232-532f3]:main():gmm-sum-accs.cc:63) Summed 5 stats, total count 412493, avg like/frame -109.397
LOG (gmm-sum-accs[5.4.232-532f3]:main():gmm-sum-accs.cc:66) Total count of stats is 412493
LOG (gmm-sum-accs[5.4.232-532f3]:main():gmm-sum-accs.cc:67) Written stats to -
LOG (gmm-est[5.4.232-532f3]:MleUpdate():transition-model.cc:517) TransitionModel::Update, objf change is 0.131509 per frame over 412493 frames.
LOG (gmm-est[5.4.232-532f3]:MleUpdate():transition-model.cc:520) 15 probabilities floored, 556 out of 1058 transition-states skipped due to insuffient data (it is normal to have some skipped.)
LOG (gmm-est[5.4.232-532f3]:main():gmm-est.cc:102) Transition model update: Overall 0.131509 log-like improvement per frame over 412493 frames.
WARNING (gmm-est[5.4.232-532f3]:MleDiagGmmUpdate():mle-diag-gmm.cc:365) Gaussian has too little data but not removing it because it is the last Gaussian: i = 0, occ = 3, weight = 1
LOG (gmm-est[5.4.232-532f3]:MleAmDiagGmmUpdate():mle-am-diag-gmm.cc:225) 0 variance elements floored in 0 Gaussians, out of 127
LOG (gmm-est[5.4.232-532f3]:MleAmDiagGmmUpdate():mle-am-diag-gmm.cc:229) Removed 0 Gaussians due to counts < --min-gaussian-occupancy=10 and --remove-low-count-gaussians=true
LOG (gmm-est[5.4.232-532f3]:main():gmm-est.cc:113) GMM update: Overall 3.3606 objective function improvement per frame over 412493 frames
LOG (gmm-est[5.4.232-532f3]:main():gmm-est.cc:116) GMM update: Overall avg like per frame = -109.397 over 412493 frames.
LOG (gmm-est[5.4.232-532f3]:SplitByCount():am-diag-gmm.cc:116) Split 127 states with target = 127, power = 0.25, perturb_factor = 0.01 and min_count = 20, split #Gauss from 127 to 127
LOG (gmm-est[5.4.232-532f3]:main():gmm-est.cc:146) Written model to exp/mono/2.mdl
# Accounting: time=0 threads=1
# Ended (code 0) at Wed Apr 24 14:38:14 CST 2019, elapsed time 0 seconds
这是迭代算法更新GMM参数的过程,详细内容这里不介绍。
monophone的训练介绍后我们需要解码(测试),解码前,我们需要构造解码图(decoding graph),也就是$H \circ C \circ L \circ G$。我们可以用下面的命令来创建解码图:
utils/mkgraph.sh --mono data/lang exp/mono exp/mono/graph
mkgraph.sh里有很多fst开头的命令,比如fsttablecompose,这些大部分都不是OpenFst里的命令,这是Kaldi实现的。我们可以看看这些命令的位置:
lili@lili-Precision-7720:~/codes/kaldi/egs/mini_librispeech/s5$ which fstdeterminizestar
/home/lili/codes/kaldi/egs/mini_librispeech/s5/../../../src/fstbin/fstdeterminizestar
这么做的原因是在语音识别中使用FST和其它地方有些不同。比如fstdeterminizestar就是”经典”的确定化算法,但是会去掉epsilon的边。更多解码图的细节请参考Decoding graph construction in Kaldi。
创建好解码图之后,我们就可以实际解码了:
steps/decode.sh --config conf/decode.config --nj 20 --cmd "$decode_cmd" \
exp/mono/graph data/test exp/mono/decode
上面的--nj指定并发的解码进程数,通常需要根据机器的资源修改。可以用下面的命令查看解码的结果:
# less exp/mono/decode/log/decode.2.log
less exp/mono/decode_nosp_tgsmall_dev_clean_2/log/decode.1.log
1272-135031-0004 THAT IS THE DISGRACING HER FRIENDS ARE ASKING FOR YOU
LOG (gmm-latgen-faster[5.4.232-532f3]:DecodeUtteranceLatticeFaster():decoder-wrappers.cc:286) Log-like per frame for utterance 1272-135031-0004 is -8.46094 over 421 frames.
上面我们可以看到1272-135031-0004解码的结果以及置信度(log likelihood)。当然上面是log的输出(也包含了解码的句子),实际的输出在exp/mono/decode/scoring/2.tra。文件名中的2代表了语言模型的scale。在RM实验里是2-13,这个值是模型的超参数,我们通常使用开发集选择最优的lm scale。
注:作者跑的mini_librispeech的结果为:
lili@lili-Precision-7720:~/codes/kaldi/egs/mini_librispeech/s5$ ls exp/mono/decode_nosp_tgsmall_dev_clean_2/scoring/
10.0.0.tra 11.0.5.tra 12.1.0.tra 14.0.0.tra 15.0.5.tra 16.1.0.tra 7.0.0.tra 8.0.5.tra 9.1.0.tra
10.0.5.tra 11.1.0.tra 13.0.0.tra 14.0.5.tra 15.1.0.tra 17.0.0.tra 7.0.5.tra 8.1.0.tra log
10.1.0.tra 12.0.0.tra 13.0.5.tra 14.1.0.tra 16.0.0.tra 17.0.5.tra 7.1.0.tra 9.0.0.tra test_filt.txt
11.0.0.tra 12.0.5.tra 13.1.0.tra 15.0.0.tra 16.0.5.tra 17.1.0.tra 8.0.0.tra 9.0.5.tra
这里和文档有一些不同(也许是文档比较老?),我这里的tra文件类似于10.0.5.tra,如果查看log可以发现这些参数的含义:
lili@lili-Precision-7720:~/codes/kaldi/egs/mini_librispeech/s5$ head exp/mono/decode_nosp_tgsmall_dev_clean_2/scoring/log/best_path.10.0.5.log
# lattice-scale --inv-acoustic-scale=10 "ark:gunzip -c exp/mono/decode_nosp_tgsmall_dev_clean_2/lat.*.gz|" ark:- | lattice-add-penalty --word-ins-penalty=0.5 ark:- ark:- | lattice-best-path --word-symbol-table=exp/mono/graph_nosp_tgsmall/words.txt ark:- ark,t:exp/mono/decode_nosp_tgsmall_dev_clean_2/scoring/10.0.5.tra
# Started at Wed Apr 24 15:25:16 CST 2019
#
lattice-add-penalty --word-ins-penalty=0.5 ark:- ark:-
lattice-best-path --word-symbol-table=exp/mono/graph_nosp_tgsmall/words.txt ark:- ark,t:exp/mono/decode_nosp_tgsmall_dev_clean_2/scoring/10.0.5.tra
lattice-scale --inv-acoustic-scale=10 'ark:gunzip -c exp/mono/decode_nosp_tgsmall_dev_clean_2/lat.*.gz|' ark:-
LOG (lattice-best-path[5.4.232-532f3]:main():lattice-best-path.cc:99) For utterance 1272-135031-0000, best cost 225.517 + 10599.8 = 10825.3 over 1087 frames.
1272-135031-0000 BECAUSE YOU'RE SPEAKING INCENTIVE CONQUERING POLTROONS PRINCES WHOSE CLIFFORD LOVABLE OLD FOR SHAGGY SISTER COMPLAINED OF
LOG (lattice-best-path[5.4.232-532f3]:main():lattice-best-path.cc:99) For utterance 1272-135031-0001, best cost 248.479 + 11079.8 = 11328.3 over 1111 frames.
1272-135031-0001 HE HAS GONE TO GONE FOR GOOD AND APPLY CRUMPLED MANAGED TO SQUEEZE INTO GIVING BESIDE DRYING IN THE HAD WITNESSED DECREASES WITH WHITE FINGERS
我们可以发现10代表--inv-acoustic-scale,也就是声学模型的(逆)的scale,也可以理解成语音模型的scale,而0.5是--word-ins-penalty,也就是对于插入错误的额外惩罚。
下面我们来看一个tra文件:
lili@lili-Precision-7720:~/codes/kaldi/egs/mini_librispeech/s5$ head exp/mono/decode_nosp_tgsmall_dev_clean_2/scor
ing/10.0.5.tra
1272-135031-0000 14207 198723 165649 86376 36528 137010 139719 194902 33332 104437 125193 64424 158810 161887 35535 124782
1272-135031-0001 78818 78075 72004 178313 72004 64424 72070 5411 6952 40763 107859 178313 166922 88672 70678 16059 51478 86219 175861 76098 196184 44342 196099 194651 62410
1272-135031-0002 84746 78469 146860 4 139840 135866 14207 84746 196011 178313 13845 125608 124782 187160 87963 64596 24220 175861 168778 29610 95041 171541 88365
1272-135031-0003 175861 102911 70495 88649 5411 159285 78983 144630 5411 125882 175861 50000
1272-135031-0004 175861 95320 63571 48238 80081 66188 197373 64424 198712
1272-135031-0005 84746 11263 80081 72070 103732 2456 5411 157742 81226 10599 24389 198712 197114 49166 163928
1272-135031-0006 84746 4233 124836 41126 86970 81226 178313 43095
1272-135031-0007 78818 52970 5411 162747 189390 167801 147427 175861 95318
1272-135031-0008 24389 86219 176496 196872 178918 77469 157892
1272-135031-0009 81505 196872 9376 3744
这里输出的是词的id,我们需要参考words.txt把它变成字符串的词。
lili@lili-Precision-7720:~/codes/kaldi/egs/mini_librispeech/s5$ ./utils/int2sym.pl -f 2- data/lang/words.txt exp/mono/decode_nosp_tgsmall_dev_clean_2/scoring/10.0.5.tra |head
1272-135031-0000 BECAUSE YOU'RE SPEAKING INCENTIVE CONQUERING POLTROONS PRINCES WHOSE CLIFFORD LOVABLE OLD FOR SHAGGY SISTER COMPLAINED OF
1272-135031-0001 HE HAS GONE TO GONE FOR GOOD AND APPLY CRUMPLED MANAGED TO SQUEEZE INTO GIVING BESIDE DRYING IN THE HAD WITNESSED DECREASES WITH WHITE FINGERS
1272-135031-0002 I HAVE REMAINED A PRISONER PLAY BECAUSE I WISH TO BE ONE OF US INSISTED FOREIGN BURST THE STONE CHANGES KIKUYU SUSTAINED INTEREST
1272-135031-0003 THE LITTLE GIRL INTIMACY AND SHE HEARD RATS AND OPENED THE DOOR
1272-135031-0004 THE KING'S FLOOD DISGRACING HER FRIENDS WRITING FOR YOU
1272-135031-0005 I BADE HER GOOD LONG AGO AND SEND HIM AWAY BUT YOU WOULD DO SO
1272-135031-0006 I ALSO OFFERED CULPABLE INDUCED HIM TO DANGLE
1272-135031-0007 HE EATS AND SLEEPS VERY STEADILY REPLIED THE KING
1272-135031-0008 BUT IN THIS WORK TOO HARD SENSUALITY
1272-135031-0009 HIS WORK AT ALL
类似的有一个perl脚本sym2int.pl把字符串变成id,比如下面的命令先把id变成符号,然后再变回去:
lili@lili-Precision-7720:~/codes/kaldi/egs/mini_librispeech/s5$ ./utils/int2sym.pl -f 2- data/lang/words.txt exp/mono/decode_nosp_tgsmall_dev_clean_2/scoring/10.0.5.tra |utils/sym2int.pl -f 2- data/lang/words.txt |head
1272-135031-0000 14207 198723 165649 86376 36528 137010 139719 194902 33332 104437 125193 64424 158810 161887 35535 124782
1272-135031-0001 78818 78075 72004 178313 72004 64424 72070 5411 6952 40763 107859 178313 166922 88672 70678 16059 51478 86219 175861 76098 196184 44342 196099 194651 62410
1272-135031-0002 84746 78469 146860 4 139840 135866 14207 84746 196011 178313 13845 125608 124782 187160 87963 64596 24220 175861 168778 29610 95041 171541 88365
1272-135031-0003 175861 102911 70495 88649 5411 159285 78983 144630 5411 125882 175861 50000
1272-135031-0004 175861 95320 63571 48238 80081 66188 197373 64424 198712
1272-135031-0005 84746 11263 80081 72070 103732 2456 5411 157742 81226 10599 24389 198712 197114 49166 163928
1272-135031-0006 84746 4233 124836 41126 86970 81226 178313 43095
1272-135031-0007 78818 52970 5411 162747 189390 167801 147427 175861 95318
1272-135031-0008 24389 86219 176496 196872 178918 77469 157892
1272-135031-0009 81505 196872 9376 3744
选项”-f 2-“的意思是从第二列开始才把id转成符号,第一列不用转,因为第一列是utterance id。
记下来执行:
lili@lili-Precision-7720:~/codes/kaldi/egs/mini_librispeech/s5$ tail exp/mono/decode_nosp_tgsmall_dev_clean_2/log/decode.2.log
LOG (gmm-latgen-faster[5.4.232-532f3]:DecodeUtteranceLatticeFaster():decoder-wrappers.cc:286) Log-like per frame for utterance 1988-24833-0026 is -7.90826 over 258 frames.
1988-24833-0027 I'LL HAVE THE CHANCE MAURICE'S CALM
LOG (gmm-latgen-faster[5.4.232-532f3]:DecodeUtteranceLatticeFaster():decoder-wrappers.cc:286) Log-like per frame for utterance 1988-24833-0027 is -8.29367 over 253 frames.
1988-24833-0028 HIS YOU LONG HAPPY LIFE
LOG (gmm-latgen-faster[5.4.232-532f3]:DecodeUtteranceLatticeFaster():decoder-wrappers.cc:286) Log-like per frame for utterance 1988-24833-0028 is -8.04841 over 293 frames.
LOG (gmm-latgen-faster[5.4.232-532f3]:main():gmm-latgen-faster.cc:176) Time taken 1494.46s: real-time factor assuming 100 frames/sec is 2.50421
LOG (gmm-latgen-faster[5.4.232-532f3]:main():gmm-latgen-faster.cc:179) Done 105 utterances, failed for 0
LOG (gmm-latgen-faster[5.4.232-532f3]:main():gmm-latgen-faster.cc:181) Overall log-likelihood per frame is -8.31865 over 59678 frames.
# Accounting: time=1496 threads=1
# Ended (code 0) at Wed Apr 24 15:11:53 CST 2019, elapsed time 1496 seconds
最后几行有一些重要信息,比如花费的时间,实时率(Real Time Factor)。这里的实时率是2.5,因此解码速度是比不上说话速度的。因为是同时解码很多文件,所以比较慢。
RM的例子使用的beam大小是20,这是为了更加准确。为了速度,实际通常beam对象是13左右。注:mini_librispeech已经是13了。
在看看这个文件的开头,它使用的解码器是gmm-latgen-faster,我们来看看它的帮助(注意每个版本都有不同的新的参数加入):
$ gmm-latgen-faster
gmm-latgen-faster
Generate lattices using GMM-based model.
Usage: gmm-latgen-faster [options] model-in (fst-in|fsts-rspecifier) features-rspecifier lattice-wspecifier [ word
s-wspecifier [alignments-wspecifier] ]
Options:
--acoustic-scale : Scaling factor for acoustic likelihoods (float, default = 0.1)
--allow-partial : If true, produce output even if end state was not reached. (bool, default = false)
--beam : Decoding beam. Larger->slower, more accurate. (float, default = 16)
--beam-delta : Increment used in decoding-- this parameter is obscure and relates to a speedup in the way the max-active constraint is applied. Larger is more accurate. (float, default = 0.5)
--delta : Tolerance used in determinization (float, default = 0.000976562)
--determinize-lattice : If true, determinize the lattice (lattice-determinization, keeping only best pdf-sequence for each word-sequence). (bool, default = true)
--hash-ratio : Setting used in decoder to control hash behavior (float, default = 2)
--lattice-beam : Lattice generation beam. Larger->slower, and deeper lattices (float, default = 10)
--max-active : Decoder max active states. Larger->slower; more accurate (int, default = 2147483647)
--max-mem : Maximum approximate memory usage in determinization (real usage might be many times this). (int, default = 50000000)
--min-active : Decoder minimum #active states. (int, default = 200)
--minimize : If true, push and minimize after determinization. (bool, default = false)
--phone-determinize : If true, do an initial pass of determinization on both phones and words (see also --word-determinize) (bool, default = true)
--prune-interval : Interval (in frames) at which to prune tokens (int, default = 25)
--word-determinize : If true, do a second pass of determinization on words only (see also --phone-determinize) (bool, default = true)
--word-symbol-table : Symbol table for words [for debug output] (string, default = "")
Standard options:
--config : Configuration file to read (this option may be repeated) (string, default = "")
--help : Print out usage message (bool, default = false)
--print-args : Print the command line arguments (to stderr) (bool, default = true)
--verbose : Verbose level (higher->more logging) (int, default = 0)
上面实际运行的参数为:
gmm-latgen-faster --max-active=7000 --beam=13.0 --lattice-beam=6.0 --acoustic-scale=0.083333
--allow-partial=true --word-symbol-table=exp/mono/graph_nosp_tgsmall/words.txt
exp/mono/final.mdl exp/mono/graph_nosp_tgsmall/HCLG.fst
"ark,s,cs:apply-cmvn --utt2spk=ark:data/dev_clean_2/split10/2/utt2spk scp:data/dev_clean_2/split10/2/cmvn.scp scp:data/dev_clean_2/split10/2/feats.scp ark:- | add-deltas ark:- ark:- |"
"ark:|gzip -c > exp/mono/decode_nosp_tgsmall_dev_clean_2/lat.2.gz"
下面是实际用到的选项:
-
max-active 解码器最大活跃的状态,越大越准确但是也越慢,默认2147483647(最大的32为有符号整数),这里是7000。
-
beam beam对象,越大越慢也越准确,默认16,这里13。
-
lattice-beam Lattice生成时的beam,越大越慢但是lattice越深,默认10,这里6.0
-
acoustic-scale 声学模型的scale,默认0.1(如果把声学模型看成1,那么语言模型的sale就是10),这里是0.083333(对应的LM scale是12)
-
allow-partial 即使最后一帧不是接受状态,也输出结果,默认false,这里为true
-
word-symbol-table 默认输出词的id,有了这个选项就输出字符串,这通常在调试时使用
下面是参数:
-
model-in 声学模型 exp/mono/final.mdl
-
(fst-in|fsts-rspecifier) FST exp/mono/graph_nosp_tgsmall/HCLG.fst
- features-rspecifier
"ark,s,cs:apply-cmvn --utt2spk=ark:data/dev_clean_2/split10/2/utt2spk scp:data/dev_clean_2/split10/2/cmvn.scp scp:data/dev_clean_2/split10/2/feats.scp ark:- | add-deltas ark:- ark:- |"- 这个很长,我们简单的解读一下:输入是data/dev_clean_2/split10/2/feats.scp,然后使用apply-cmvn对它进行Ceptral Mean and Variance Normalization。执行这个命令需要传入utt2spk,这个文件告诉它每个utterance id对于的说话人id。此外还有一个cmvn.scp,这是训练数据里统计的Ceptral的均值和方差。
- 然后再重定向给add-deltas,把13维的MFCC特征加上Delta和Delta-Delta,变成39维。
- lattice-wspecifier
"ark:|gzip -c > exp/mono/decode_nosp_tgsmall_dev_clean_2/lat.2.gz"
就是输出ark文件,但是压缩一下。
- 显示Disqus评论(需要科学上网)