本文详细介绍BERT模型的原理,包括相关的ELMo和OpenAI GPT模型。阅读本文需要先学习Transformer模型,不了解的读者可以先阅读Transformer图解和Transformer代码阅读。
目录
背景简介
2018年深度学习在NLP领域取得了比较大的突破,最大的新闻当属Google的BERT模型横扫各大比赛的排行榜。作者认为,深度学习在NLP领域比较重点的三大突破为:Word Embedding、RNN/LSTM/GRU+Seq2Seq+Attention+Self-Attention机制和Contextual Word Embedding(Universal Sentence Embedding)。
Word Embedding解决了传统机器学习方法的特征稀疏问题,它通过把一个词映射到一个低维稠密的语义空间,从而使得相似的词可以共享上下文信息,从而提升泛化能力。而且通过无监督的训练可以获得高质量的词向量(比如Word2vec和Glove等方法),从而把这些语义知识迁移到数据较少的具体任务上。但是Word Embedding学到的是一个词的所有语义,比如bank可以是”银行”也可以是”水边。如果一定要用一个固定的向量来编码其语义,那么我们只能把这两个词的语义都编码进去,但是实际一个句子中只有一个语义是合理的,这显然是有问题的。
这时我们可以通过RNN/LSTM/GRU来编码上下文的语义,这样它能学到如果周围是money,那么bank更可能是”银行”的语义。最原始的RNN由于梯度消失和梯度爆炸等问题很难训练,后来引入了LSTM和GRU等模型来解决这个问题。最早的RNN只能用于分类、回归和序列标注等任务,通过引入两个RNN构成的Seq2Seq模型可以解决序列的变换问题。比如机器翻译、摘要、问答和对话系统都可以使用这个模型。尤其机器翻译这个任务的训练数据比较大,使用深度学习的方法的效果已经超过传统的机器学习方法,而且模型结构更加简单。到了2017年,Google提出了Transformer模型,引入了Self-Attention。Self-Attention的初衷是为了用Attention替代LSTM,从而可以更好的并行(因为LSTM的时序依赖特效很难并行),从而可以处理更大规模的语料。Transformer出来之后被广泛的用于以前被RNN/LSTM/GRU霸占的地盘,Google更是在Transformer的论文里使用”Attention is all you need”这样霸气的标题。现在Transformer已经成为Encoder/Decoder的霸主。
虽然RNN可以学到上下文的信息,但是这些上下文的语义是需要通过特定任务的标注数据使用来有监督的学习。很多任务的训练数据非常少并且获取成本很高,因此在实际任务中RNN很难学到复杂的语义关系。当然通过Multi-Task Learning,我们可以利用其它相关任务的数据。比如我们要做文本分类,我们可以利用机器翻译的训练数据,通过同时优化两个(多个)目标,让模型同时学到两个任务上的语义信息,因为这两个任务肯定是共享很多基础语义信息的,所以它的效果要比单个任务好。但即使这样,标注的数据量还是非常有限的。
因此2018年的研究热点就变成了怎么利用无监督的数据学习Contextual Word Embedding(也叫做Universal Sentence Embedding),也就是通过无监督的方法,让模型能够学到一个词在不同上下文的不同语义表示方法。当然这个想法很早就有了,比如2015年的Skip Thought Vector,但是它只使用了BookCorpus,这只有一万多本书,七千多万个句子,因此效果并没有太明显的提升。
在BERT之前比较大的进展是ELMo、ULMFiT和OpenAI GPT。尤其是OpenAI GPT,它在BERT出现之前已经横扫过各大排行榜一次了,当然Google的BERT又横扫了一次。
UMLFiT比较复杂,而且效果也不是特别好,我们暂且不提。ELMo和OpenAI GPT的思想其实非常非常简单,就是用海量的无标注数据学习语言模型,在学习语言模型的过程中自然而然的就学到了上下文的语义关系。它们都是来学习一个语言模型,前者使用的是LSTM而后者使用Transformer,在进行下游任务处理的时候也有所不同,ELMo是把它当成特征。拿分类任务来说,输入一个句子,ELMo用LSTM把它扫一次,这样就可以得到每个词的表示,这个表示是考虑上下文的,因此”He deposited his money in this bank”和”His soldiers were arrayed along the river bank”中的两个bank的向量是不同的。下游任务用这些向量来做分类,它会增加一些网络层,但是ELMo语言模型的参数是固定的。而OpenAI GPT不同,它直接用特定任务来Fine-Tuning Transformer的参数。因为用特定任务的数据来调整Transformer的参数,这样它更可能学习到与这个任务特定的上下文语义关系,因此效果也更好。
而BERT和OpenAI GPT的方法类似,也是Fine-Tuning的思路,但是它解决了OpenAI GPT(包括ELMo)单向信息流的问题,同时它的模型和语料库也更大。依赖Google强大的计算能力和工程能力,BERT横扫了OpenAI GPT。成王败寇,很少还有人记得OpenAI GPT的贡献了。但是BERT的很多思路都是沿用OpenAI GPT的,要说BERT的学术贡献,最多是利用了Mask LM(这个模型在上世纪就存在了)和Predicting Next Sentence这个Multi-task Learning而已。
Skip Thought Vector
简介
我们之前学习过word2vec,其中一种模型是Skip-Gram模型,根据中心词预测周围的(context)词,这样我们可以学到词向量。那怎么学习到句子向量呢?一种很自然想法就是用一个句子预测它周围的句子,这就是Skip Thought Vector的思路。它需要有连续语义相关性的句子,比如论文中使用的书籍。一本书由很多句子组成,前后的句子是有关联的。那么我们怎么用一个句子预测另一个句子呢?这可以使用Encoder-Decoder,类似于机器翻译。
比如一本书里有3个句子”I got back home”、”I could see the cat on the steps”和”This was strange”。我们想用中间的句子”I could see the cat on the steps.”来预测前后两个句子。如下图所示,输入是句子”I could see the cat on the steps.”,输出是两个句子”I got back home.”和”This was strange.”。
 图:Skip Thought Vector
图:Skip Thought Vector
我们首先用一个Encoder(比如LSTM或者GRU)把输入句子编码成一个向量。而右边是两个Decoder(我们任务前后是不对称的,因此用两个Decoder)。因为我们不需要预测(像机器翻译那样生成一个句子),所以我们只考虑Decoder的训练。Decoder的输入是”<eos> I got back home”,而Decoder的输出是”I got back home <eos>”。
经过训练之后,我们就得到了一个Encoder(Decoder不需要了)。给定一个新的句子,我们可以把它编码成一个向量。这个向量可以用于下游(down stream)的任务,比如情感分类,语义相似度计算等等。
训练数据集
和训练Word2Vec不同,Word2Vec只需要提供句子,而Skip Thought Vector需要文章(至少是段落)。论文使用的数据集是BookCorpus(http://yknzhu.wixsite.com/mbweb),目前网站已经不提供下载了。BookCorpus的统计信息如下图所示,有一万多本书,七千多万个句子。
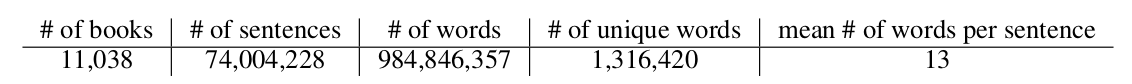 图:BookCorpus统计信息
图:BookCorpus统计信息
模型
接下来我们介绍一些论文中使用的模型,注意这是2015年的论文,过去好几年了,其实我们是可以使用更新的模型。但是基本的思想还是一样的。
Encoder是一个GRU。假设句子$s_i=w_i^1…w_i^N$,t时刻的隐状态是$h_i^t$认为编码了字符串$w_i^1…w_i^t$的语义,因此$h_i^N$可以看成对整个句子语义的编码。t时刻GRU的计算公式为:
\[\begin{split} r^t & =\sigma(W_rx^t+U_rh^{t-1}) \\ z^t & =\sigma(W_zx^t+U_zh^{t-1}) \\ \bar{h}^t & =tanh(Wx^t+U(r^t \odot h^{t-1})) \\ h^t & =(1-z^t) \odot h^{t-1} + z^t \odot \bar{h}^t \end{split}\]这就是标准的GRU,其中$x^t$是$w_i^t$的Embedding向量,$r^t$是重置(reset)门,$z^t$是更新(update)门,$\odot$是element-wise的乘法。Decoder是一个神经网络语言模型。
\[\begin{split} r^t & = \sigma(W_r^dx^{t-1} + U_r^dh^{t-1} + C_rh_i) \\ z^t & = \sigma(W_z^dx^{t-1} + U_z^dh^{t-1} + C_zh_i) \\ \bar{h}^t & =tanh(W^dx^{t-1} + U^d(r^t \odot h^{t-1}) +Ch_i) \\ h^t & =(1-z^t) \odot h^{t-1} + z^t \odot \bar{h}^t \end{split}\]和之前我们在机器翻译里介绍的稍微有一些区别。标准Encoder-Decoder里Decoder每个时刻的输入是$x^{t-1}$和$h^{t-1}$,Decoder的初始状态设置为Encoder的输出$h_i$。而这里Decodert时刻的输入除了$x^{t-1}$和$h^{t-1}$,还有Encoder的输出$h_i$。
计算出Decoder每个时刻的隐状态$h^t$之后,我们在用一个矩阵V把它投影到词的空间,输出的是预测每个词的概率分布。注意:预测前一个句子和后一个句子是两个GRU模型,它们的参数是不共享的,但是投影矩阵V是共享的。当然输入$w^t$到Embedding $x^t$的Embedding矩阵也是共享的。和Word2Vec对比的话,V是输出向量(矩阵)而这个Embedding(这里没有起名字)是输入向量(矩阵)。
词汇扩展
这篇论文还有一个比较重要的方法就是词汇扩展。因为BookCorpus相对于训练Word2Vec等的语料来说还是太小,很多的词都根本没有在这个语料中出现,因此直接使用的话效果肯定不好。
本文使用了词汇扩展的办法。具体来说我们可以先用海量的语料训练一个Word2Vec,这样可以把一个词映射到一个语义空间,我们把这个向量叫作$\mathcal{V}_{w2v}$。而我们之前训练的得到的输入向量也是把一个词映射到另外一个语义空间,我们记作\(\mathcal{V}_{rnn}\)。
我们假设它们之间存在一个线性变换\(f: \mathcal{V}_{w2v} \rightarrow \mathcal{V}_{rnn}\)。这个线性变换的参数是矩阵W,使得\(v_{rnn}=Wv_{w2v}\)。那怎么求这个变换矩阵W呢?因为两个训练语料会有公共的词(通常训练word2vec的语料比skip vector大得多,从而词也多得多)。因此我们可以用这些公共的词来寻找W。寻找的依据是:遍历所有可能的W,使得$Wv_{w2v}$和$v_{rnn}$尽量接近。用数学语言描述就是:
\[W^* = \underset{W}{argmin} \sum_{w \in both set} |Wv_{w2v}(w)-v_{rnn}(w)|^2\]训练细节
首先训练了单向的GRU,向量的维度是2400,我们把它叫作uni-skip向量。此外还训练了bi-skip向量,它是这样得到的:首先训练1200维的uni-skip,然后句子倒过来,比如原来是”aa bb”、”cc dd”和”ee ff”,我们是用”cc dd”来预测”aa bb”以及”ee ff”,现在反过来变成”ff ee”、”dd cc”和”bb aa”。这样也可以训练一个模型,当然也就得到一个encoder(两个decoder不需要了),给定一个句子我们把它倒过来然后也编码成1200为的向量,最后把这个两个1200维的向量拼接成2400维的向量。
模型训练完成之后还需要进行词汇扩展。通过BookCorpus学习到了20,000个词,而word2vec共选择了930,911词,通过它们共同的词学习出变换矩阵W,从而使得我们的Skip Thought Vector可以处理930,911个词。
实验
为了验证效果,本文把Sentence Embedding作为下游任务的输入特征,任务包括分类(情感分类),SNI(RTE)等。前者的输入是一个句子,而后者的输入是两个句子。
Semantic relatedness任务
这里使用了SICK(SemEval 2014 Task 1,给定两个句子,输出它们的语义相关性1-5五个分类)和Microsoft Paraphrase Corpus(给定两个句子,判断它们是否一个意思/两分类)。
它们的输入是两个句子,输出是分类数。对于输入的两个句子,我们用Skip Thought Vector把它们编码成两个向量u和v,然后计算$u \cdot v$与$\vert u-v \vert $,然后把它们拼接起来,最后接一个logistic regression层(全连接加softmax)。
使用这么简单的分类模型的原因是想看看Sentence Embedding是否能够学习到复杂的非线性的语义关系。使用结果如下图所示。可以看到效果还是非常不错的,和(当时)最好的结果差别不大,而那些结果都是使用非常复杂的模型得到结果,而这里只使用了简单的逻辑回归模型。
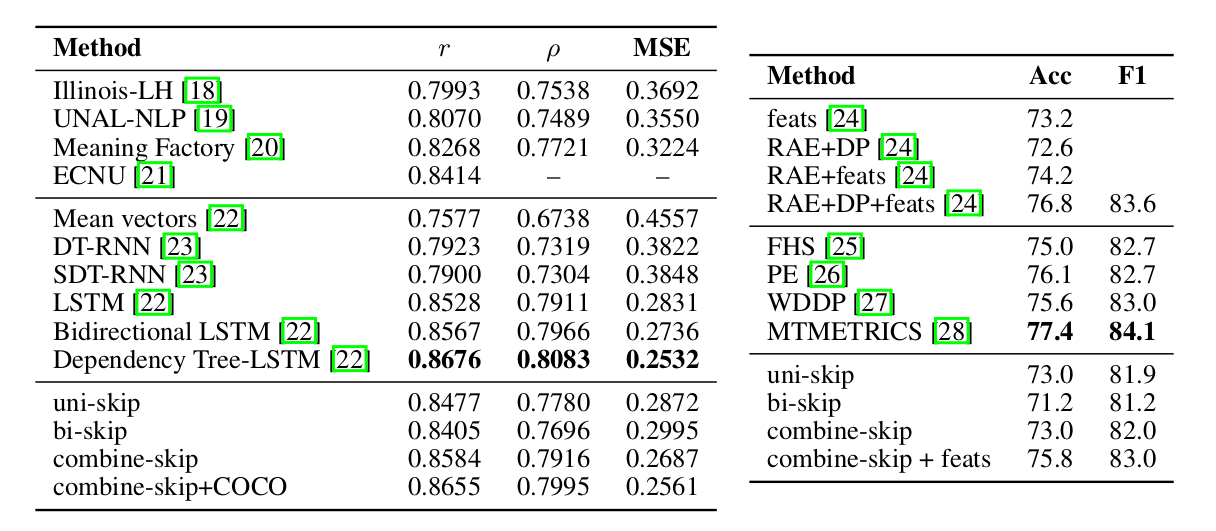 图:Semantic relatedness的效果
图:Semantic relatedness的效果
COCO图像检索任务
这个任务的输入是一幅图片和一个句子,模型输出的是它们的相关性(句子是否描述了图片的内容)。句子我们可以用Skip Thought Vector编码成一个向量;而图片也可以用预训练的CNN编码成一个向量。模型细节这里不再赘述了,最终的结果如下图所示。
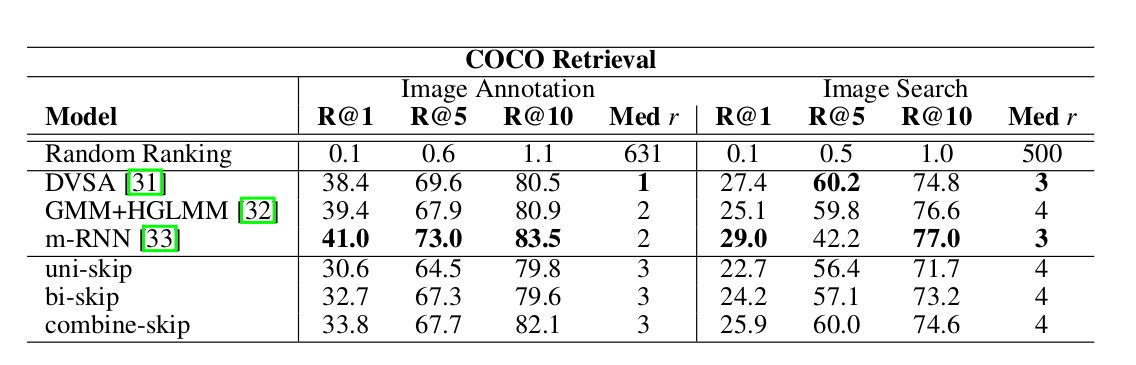 图:Image Retrieval的效果
图:Image Retrieval的效果
分类任务
这里比较了5个分类任务: 电影评论情感分类(MR), 商品评论情感分类(CR) , 主观/客观分类(SUBJ), 意见分类(MPQA)和TREC问题类型分类。结果如下图所示。
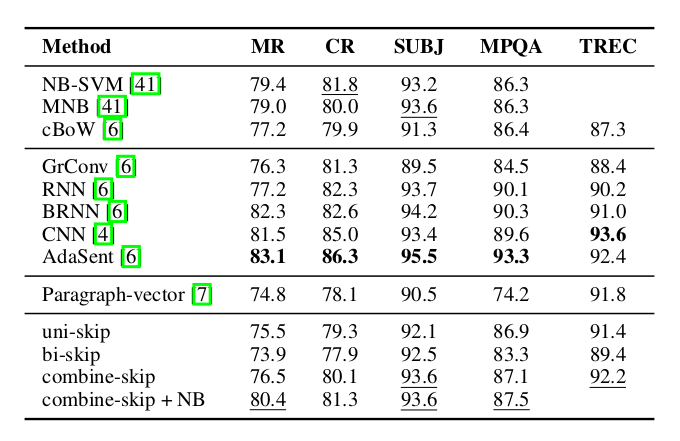 图:分类任务的效果
图:分类任务的效果
ELMo
简介
ELMo是Embeddings from Language Models的缩写,意思就是语言模型得到的(句子)Embedding。另外Elmo是美国儿童教育电视节目芝麻街(Sesame Street)里的小怪兽的名字。原始论文是Deep contextualized word representations,这个标题是很合适的,也就是用深度的Transformer模型来学习上下文相关的词表示。
 图:Elmo
图:Elmo
这篇论文的想法其实非常非常简单,但是取得了非常好的效果。它的思路是用深度的双向RNN(LSTM)在大量未标注数据上训练语言模型,如下图所示。然后在实际的任务中,对于输入的句子,我们使用这个语言模型来对它处理,得到输出的向量,因此这可以看成是一种特征提取。但是和普通的Word2Vec或者GloVe的pretraining不同,ELMo得到的Embedding是有上下文的。比如我们使用Word2Vec也可以得到词”bank”的Embedding,我们可以认为这个Embedding包含了bank的语义。但是bank有很多意思,可以是银行也可以是水边,使用普通的Word2Vec作为Pretraining的Embedding,只能同时把这两种语义都编码进向量里,然后靠后面的模型比如RNN来根据上下文选择合适的语义——比如上下文有money,那么它更可能是银行;而如果上下文是river,那么更可能是水边的意思。但是RNN要学到这种上下文的关系,需要这个任务有大量相关的标注数据,这在很多时候是没有的。而ELMo的特征提取可以看成是上下文相关的,如果输入句子有money,那么它就(或者我们期望)应该能知道bank更可能的语义,从而帮我们选择更加合适的编码。
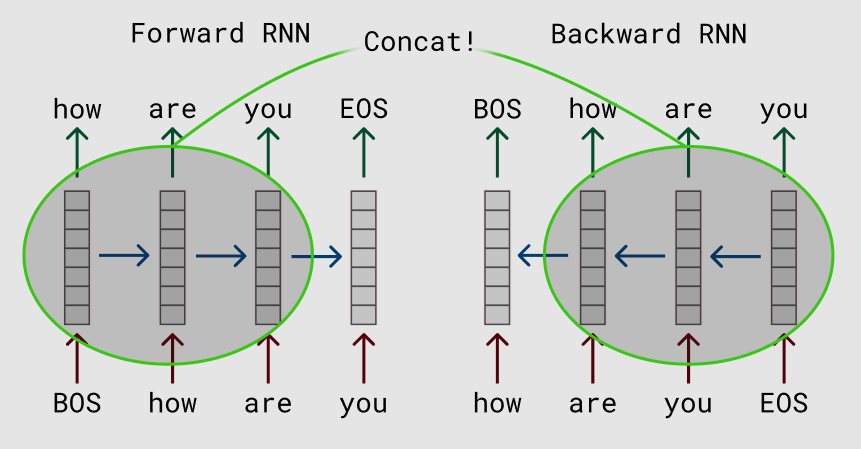 图:RNN语言模型
图:RNN语言模型
无监督的预训练
给定一个长度为N的句子,假设为$t_1,t_2,…,t_N$,语言模型会计算给定$t_1,…,t_{k-1}$的条件下出现$t_k$的概率:
\[p(t_1,...,t_N)=\prod_{i=1}^{k}p(t_k|t_1,...,t_{k-1})\]传统的N-gram语言模型不能考虑很长的历史,因此现在的主流是使用多层双向的RNN(LSTM/GRU)来实现语言模型。在每个时刻k,RNN的第j层会输出一个隐状态\(\overrightarrow{h}_{kj}^{LM}\),其中$j=1,2,…,L$,L是RNN的层数。最上层是\(\overrightarrow{h}_{kL}^{LM}\),对它进行softmax之后就可以预测输出词的概率。类似的,我们可以用一个反向的RNN来计算概率:
\[p(t_1,...,t_N)=\prod_{i=1}^{k}p(t_k|t_{k+1},...,t_N)\]通过这个RNN,我们可以得到$\overleftarrow{h}_{kj}^{LM}$。我们把这两个方向的RNN合并起来就得到Bi-LSTM。我们优化的损失函数是两个LSTM的交叉熵加起来是最小的:
\[Loss=\sum_{k=1}^{N}(logp(t_k|t_1,...,t_{k-1};\Theta_x,\overrightarrow{\Theta}_{LSTM},\Theta_s) + logp(t_k|t_{k+1},...,t_N;\Theta_x,\overleftarrow{\Theta}_{LSTM},\Theta_s)\]这两个LSTM有各自的参数\(\overrightarrow{\Theta}_{LSTM}\)和\(\overleftarrow{\Theta}_{LSTM}\),但是word embedding参数$\Theta_x$和softmax参数$\Theta_s$是共享的。
应用ELMo
ELMo会根据不同的任务,把上面得到的双向的LSTM的不同层的隐状态组合起来。对于输入的词$t_k$,我们可以得到2L+1个向量,分别是\(\{x_k^{LM}, \overrightarrow{h}_{kj}^{LM}, \overleftarrow{h}_{kj}^{LM}, j=1,2,...,L\}\),我们把它记作\(R_k=\{h_{kj}^{LM}, j=0,1,...,L\}\)。其中\(h_{k0}^{LM}\)是词的Embedding,它与上下文无关,而其它的\(h_{kj}^{LM}=[\overrightarrow{h}_{kj}^{LM}; \overleftarrow{h}_{kj}^{LM}], j>0\)是把双向的LSTM的输出拼接起来的,它们与上下文相关的。为了用于下游(downstream)的特定任务,我们会把不同层的隐状态组合起来,组合的参数是根据特定任务学习出来的,公式如下:
\[ELMo_k^{task}=E(R_k;\Theta_{task})=\gamma^{task}\sum_{j=0}^{L}s_j^{task}h_{kj}^{LM}\]这里的$\gamma^{task}$是一个缩放因子,而$s_j^{task}$用于把不同层的输出加权组合出来。在实际的任务中,RNN的参数$h_{kj}^{LM}$都是固定的,可以调的参数只是$\gamma^{task}$和$s_j^{task}$。当然这里ELMo只是一个特征提取,实际任务会再加上一些其它的网络结构,那么那些参数也是一起调整的。
实验结果
下图是ELMo在SQuAD、SNLI等常见任务上的效果,相对于Baseline系统都有不小的提高。
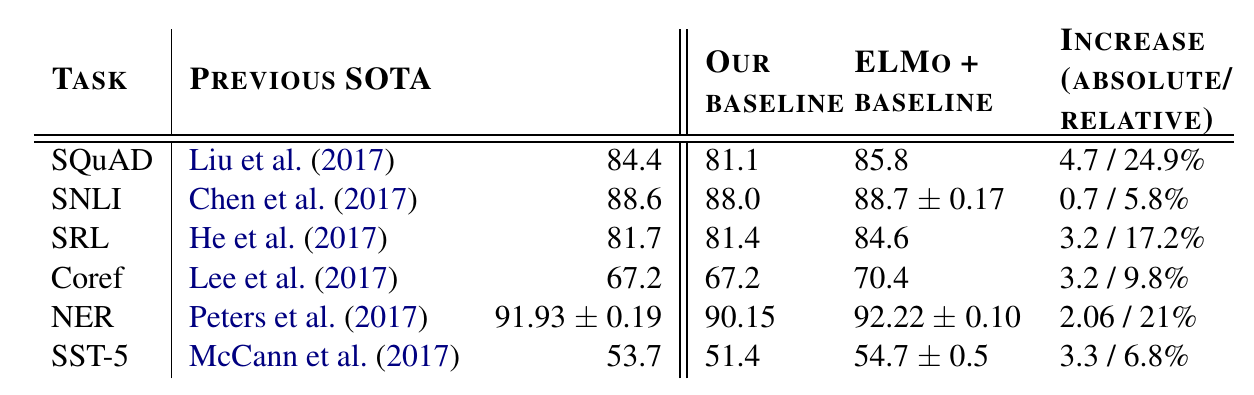 图:ELMo的效果
图:ELMo的效果
OpenAI GPT
OpenAI GPT是来自OpenAI的论文Improving Language Understanding by Generative Pre-Training,BERT借鉴了很多它的方法。
简介
和前面的ELMo不同,GPT得到的语言模型的参数不是固定的,它会根据特定的任务进行调整(通常是微调),这样得到的句子表示能更好的适配特定任务。它的思想其实也很简单,使用Transformer来学习一个语言模型,对句子进行无监督的Embedding,然后根据具体任务对Transformer的参数进行微调。
无监督的Pretraining
之前我们介绍的Transformer模型是用来做机器翻译的,它有一个Encoder和一个Decoder。这里使用的是Encoder,只不过Encoder的输出不是给Decoder使用,而是直接用它来预测下一个词,如下图所示。但是直接用Self-Attention来训练语言模型是有问题的,因为在k时刻$p(t_k \vert t_1,..,t_{k-1})$,也就是计算$t_k$的时候只能利用它之前的词(或者逆向的语言模型只能用它之后的词)。但是Transformer的Self-Attention是可以利用整个句子的信息的,这显然不行,因为你让它根据”it is a”来预测后面的词,而且还告诉它整个句子是”it is a good day”,它就可能”作弊”,直接把下一个词输出了,这样loss是零。
因此这里要借鉴Decoder的Mask技巧,通过Mask让它在编码$t_k$的时候只能利用k之前(包括k本身)的信息。具体来说,给定一个未标注的语料库$\mathcal{U}=\{u_1,…,u_n\}$,我们训练一个语言模型,对参数进行最大(对数)似然估计:
\[L_1(\mathcal{U})=\sum_i logP(u_i|u_1,...,u_{k-1})\]我们这里使用多层的Transformer来实现语言模型,具体为:
\[\begin{split} h_0 & =UW_e+W_p \\ h_l & = transformer\_block(h_{l-1}) \\ P(u) & = softmax(h_n W_e^T) \end{split}\]这里的$W_e$是词的Embedding Matrix,$W_p$是位置Embedding Matrix。注意这里的位置编码没有使用前面Transformer的固定编码方式,而是采用类似词的Embedding Matrix,让它自己根据任务学习出合适的位置编码。
监督的Fine-Tuning
无监督的Pretraining之后,我们还需要针对特定任务进行Fine-Tuning。我们先假设监督数据集合$\mathcal{C}$的输入x是一个词序列(后面会讲到怎么处理相似度计算或者问答这种输入有两个序列的问题)$x^1,…,x^m$,输出是一个分类的标签y,比如情感分类(Sentiment Classification)任务就是满足上述的条件。
我们把$x^1,…,x^m$输入Transformer模型,得到最上层的最后一个时刻的输出$h_l^m$,然后我们再加一个softmax层(参数为$W_y$)进行分类,最后用交叉熵损失函数计算损失,从而根据标准数据调整Transformer的参数以及softmax的参数$W_y$。这等价于最大似然估计:
\[L_2(\mathcal{C})=\sum{x,y}logP(y|x^1,...,x^m)\]正常我们应该调整参数使得$L_2$最大,但是为了提高训练速度和模型的泛化能力,我们使用Multi-task Learning,同时让它最大似然$L_1$和$L_2$:
\[L_3(\mathcal{C})=L_2(\mathcal{C})+\lambda \times L_1(\mathcal{C})\]注意,这里使用的$L_1$还是之前的语言模型的损失(似然),但是使用的数据不是前面无监督的数据$\mathcal{U}$,而是使用简单的数据$\mathcal{C}$,而且只使用其中的x,而不需要标签y。
其它任务
前面讲了,我们能够处理的任务要求输入是一个序列,而输出是一个分类标签。对于有些任务,比如情感分类,这是没有问题的,但是对于相似度计算或者问答,输入是两个序列。为了能够使用GPT,我们需要一些特殊的技巧把两个输入序列变成一个输入序列。
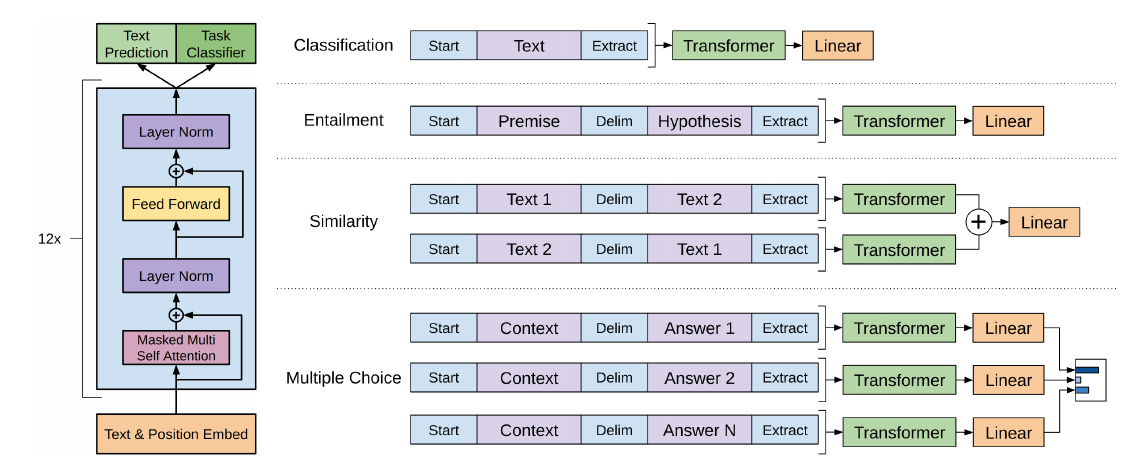 图:处理其它任务
图:处理其它任务
如图上图所示,对于输入是一个序列的任务,我们在序列前后增加两个特殊token——”start”和”extract”,分别表示开始和结束;而如果输入是两个序列,那么在它们中间增加一个特殊的token “delim”。比如Entailment,输入是Premise和Hypothesis,输出是3个分类标签中的一个。
如果是相似度计算,因为对称性,我们把它们交换顺序,然后输入两个Transformer。如果是多选题,比如给定一个问题和N个答案,那么我们可以把问题和N个答案分别输入N个Transformer。
实验结果
下图是部分实验结果,相对于之前的baseline对很多任务都有提高。
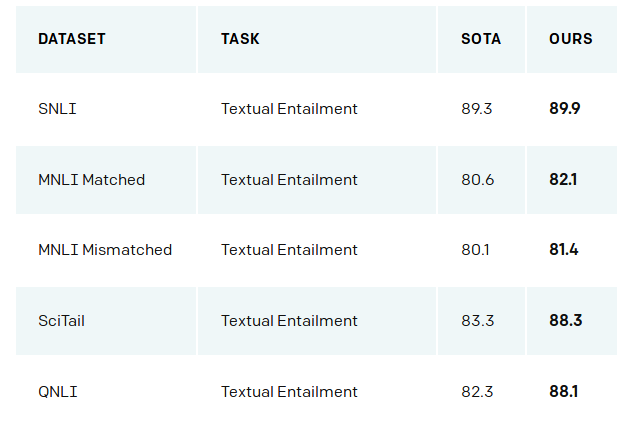 图:OpenAI GPT的部分实验结果
图:OpenAI GPT的部分实验结果
BERT
ELMo和OpenAI GPT的问题
ELMo和GPT最大的问题就是传统的语言模型是单向的——我们是根据之前的历史来预测当前词。但是我们不能利用后面的信息。比如句子”The animal didn’t cross the street because it was too tired”。我们在编码it的语义的时候需要同时利用前后的信息,因为在这个句子中,it可能指代animal也可能指代street。根据tired,我们推断它指代的是animal,因为street是不能tired。但是如果把tired改成wide,那么it就是指代street了。传统的语言模型,不管是RNN还是Transformer,它都只能利用单方向的信息。比如前向的RNN,在编码it的时候它看到了animal和street,但是它还没有看到tired,因此它不能确定it到底指代什么。如果是后向的RNN,在编码的时候它看到了tired,但是它还根本没看到animal,因此它也不能知道指代的是animal。Transformer的Self-Attention理论上是可以同时attend to到这两个词的,但是根据前面的介绍,由于我们需要用Transformer来学习语言模型,因此必须用Mask来让它看不到未来的信息,所以它也不能解决这个问题的。
注意:即使ELMo训练了双向的两个RNN,但是一个RNN只能看一个方向,因此也是无法”同时”利用前后两个方向的信息的。也许有的读者会问,我的RNN有很多层,比如第一层的正向RNN在编码it的时候编码了animal和street的语义,反向RNN编码了tired的语义,然后第二层的RNN就能同时看到这两个语义,然后判断出it指代animal。理论上是有这种可能,但是实际上很难。举个反例,理论上一个三层(一个隐层)的全连接网络能够拟合任何函数,那我们还需要更多层词的全连接网络或者CNN、RNN干什么呢?如果数据不是足够足够多,如果不对网络结构做任何约束,那么它有很多中拟合的方法,其中很多是过拟合的。但是通过对网络结构的约束,比如CNN的局部特效,RNN的时序特效,多层网络的层次结构,对它进行了很多约束,从而使得它能够更好的收敛到最佳的参数。我们研究不同的网络结构(包括resnet、dropout、batchnorm等等)都是为了对网络增加额外的(先验的)约束。
BERT简介
BERT来自Google的论文Pre-training of Deep Bidirectional Transformers for Language Understanding,BERT是”Bidirectional Encoder Representations from Transformers”的首字母缩写。如下图所示,BERT能够同时利用前后两个方向的信息,而ELMo和GPT只能使用单个方向的。
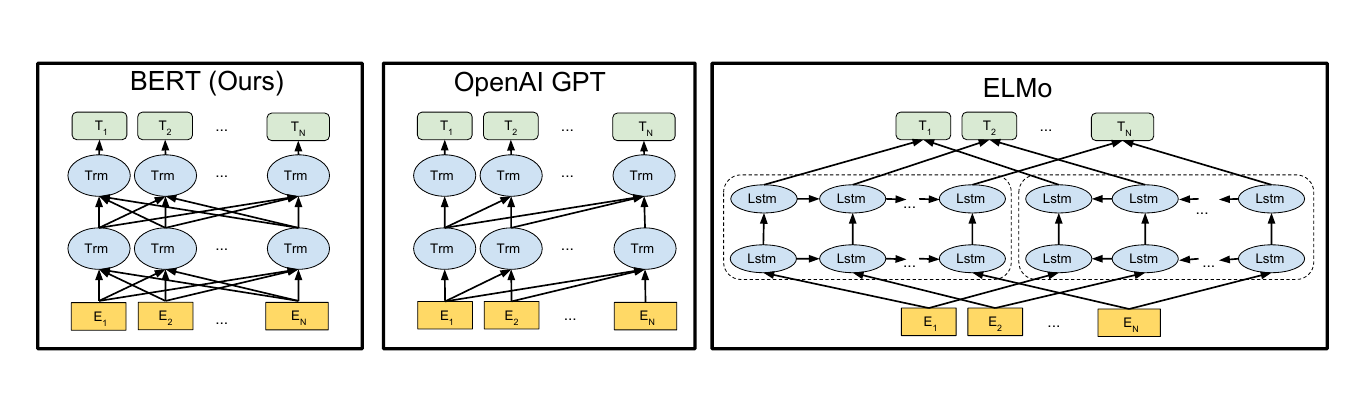 图:BERT vs ELMo and GPT
图:BERT vs ELMo and GPT
BERT仍然使用的是Transformer模型,那它是怎么解决语言模型只能利用一个方向的信息的问题呢?答案是它的pretraining训练的不是普通的语言模型,而是Mask语言模型。在介绍Mask语言模型之前我们先介绍BERT的输入表示。
输入表示
BERT的输入表示如图下图所示。比如输入的是两个句子”my dog is cute”,”he likes playing”。后面会解释为什么需要两个句子。这里采用类似GPT的两个句子的表示方法,首先会在第一个句子的开头增加一个特殊的Token [CLS],在cute的后面增加一个[SEP]表示第一个句子结束,在##ing后面也会增加一个[SEP]。注意这里的分词会把”playing”分成”play”和”##ing”两个Token,这种把词分成更细粒度的Word Piece的方法在前面的机器翻译部分介绍过了,这是一种解决未登录词的常见办法,后面的代码部分也会简单介绍。接着对每个Token进行3个Embedding:词的Embedding;位置的Embedding和Segment的Embedding。词的Embedding大家都很熟悉了,而位置的Embedding和词类似,把一个位置(比如2)映射成一个低维稠密的向量。而Segment只有两个,要么是属于第一个句子(segment)要么属于第二个句子,不管那个句子,它都对应一个Embedding向量。同一个句子的Segment Embedding是共享的,这样它能够学习到属于不同Segment的信息。对于情感分类这样的任务,只有一个句子,因此Segment id总是0;而对于Entailment任务,输入是两个句子,因此Segment是0或者1。
BERT模型要求有一个固定的Sequence的长度,比如128。如果不够就在后面padding,否则就截取掉多余的Token,从而保证输入是一个固定长度的Token序列,后面的代码会详细的介绍。第一个Token总是特殊的[CLS],它本身没有任何语义,因此它会(必须)编码整个句子(其它词)的语义。
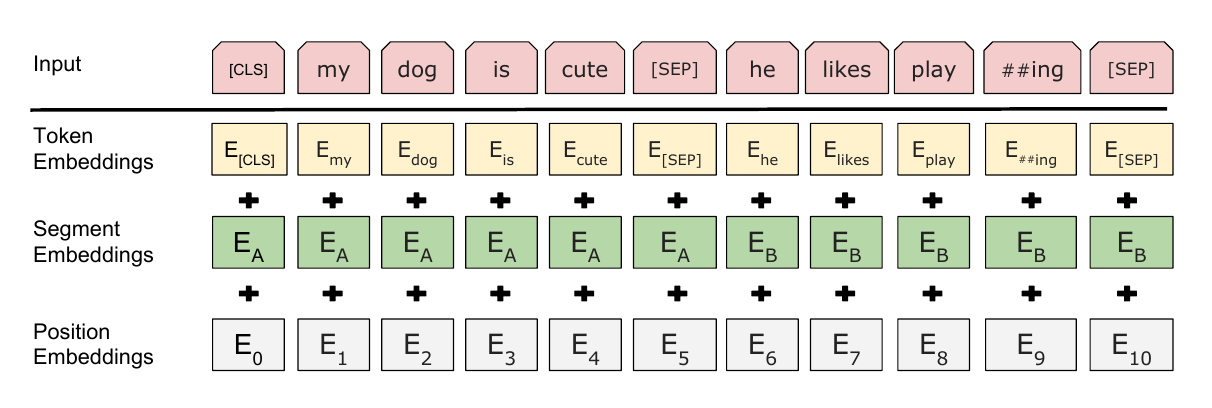 图:BERT的输入表示
图:BERT的输入表示
Mask LM
为了解决只能利用单向信息的问题,BERT使用的是Mask语言模型而不是普通的语言模型。Mask语言模型有点类似与完形填空——给定一个句子,把其中某个词遮挡起来,让人猜测可能的词。这里会随机的Mask掉15%的词,然后让BERT来预测这些Mask的词,通过调整模型的参数使得模型预测正确的概率尽可能大,这等价于交叉熵的损失函数。这样的Transformer在编码一个词的时候会(必须)参考上下文的信息。
但是这有一个问题:在Pretraining Mask LM时会出现特殊的Token [MASK],但是在后面的fine-tuning时却不会出现,这会出现Mismatch的问题。因此BERT中,如果某个Token在被选中的15%个Token里,则按照下面的方式随机的执行:
- 80%的概率替换成[MASK],比如my dog is hairy → my dog is [MASK]
- 10%的概率替换成随机的一个词,比如my dog is hairy → my dog is apple
- 10%的概率替换成它本身,比如my dog is hairy → my dog is hairy
这样做的好处是,BERT并不知道[MASK]替换的是哪一个词,而且任何一个词都有可能是被替换掉的,比如它看到的apple可能是被替换的词。这样强迫模型在编码当前时刻的时候不能太依赖于当前的词,而要考虑它的上下文,甚至更加上下文进行”纠错”。比如上面的例子模型在编码apple是根据上下文my dog is应该把apple(部分)编码成hairy的语义而不是apple的语义。
预测句子关系
在有些任务中,比如问答,前后两个句子有一定的关联关系,我们希望BERT Pretraining的模型能够学习到这种关系。因此BERT还增加了一个新的任务——预测两个句子是否有关联关系。这是一种Multi-Task Learing。BERT要求的Pretraining的数据是一个一个的”文章”,比如它使用了BookCorpus和维基百科的数据,BookCorpus是很多本书,每本书的前后句子是有关联关系的;而维基百科的文章的前后句子也是有关系的。对于这个任务,BERT会以50%的概率抽取有关联的句子(注意这里的句子实际只是联系的Token序列,不是语言学意义上的句子),另外以50%的概率随机抽取两个无关的句子,然后让BERT模型来判断这两个句子是否相关。比如下面的两个相关的句子:
[CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
下面是两个不相关的句子:
[CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Fine-Tuning
BERT的Fine-Tuning如下图所示,共分为4类任务。
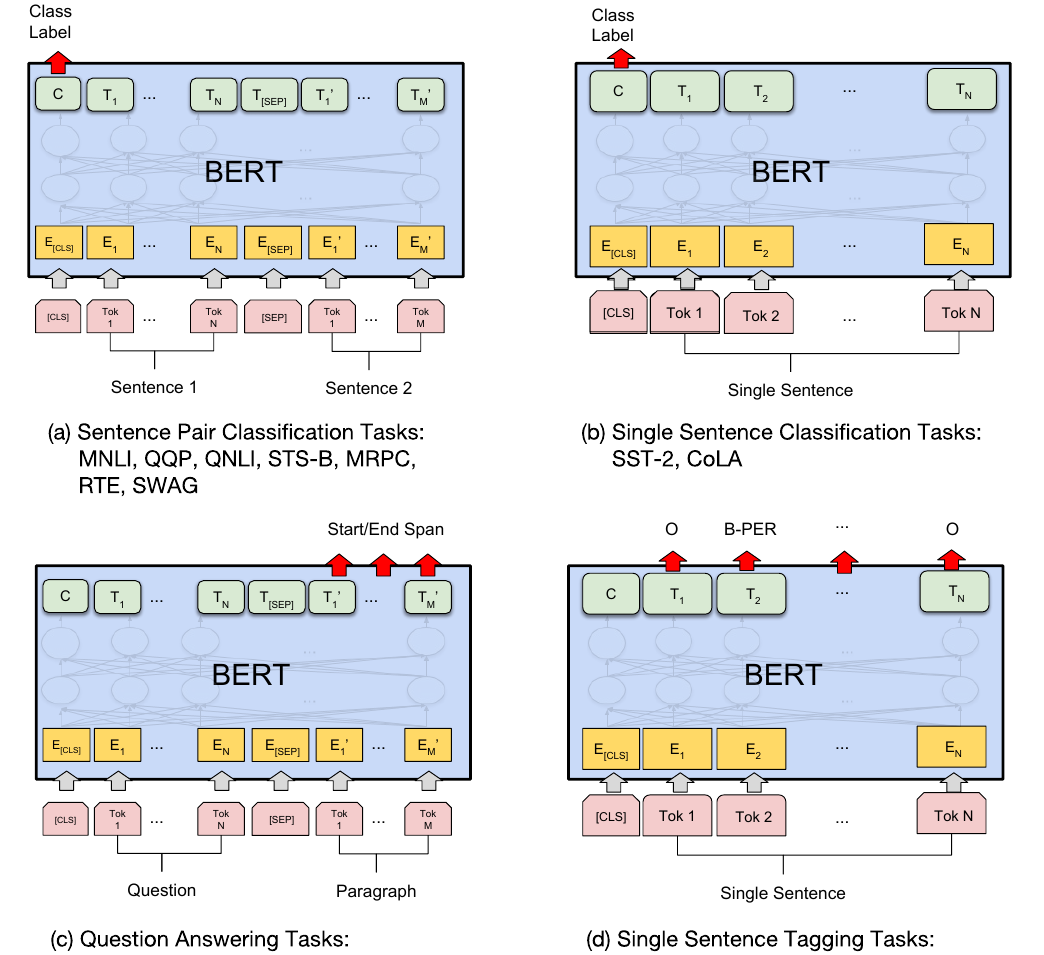 图:BERT的Fine-Tuning
图:BERT的Fine-Tuning
对于普通的分类任务,输入是一个序列,如图中右上所示,所有的Token都是属于同一个Segment(Id=0),我们用第一个特殊Token [CLS]的最后一层输出接上softmax进行分类,用分类的数据来进行Fine-Tuning。
对于相似度计算等输入为两个序列的任务,过程如图左上所示。两个序列的Token对应不同的Segment(Id=0/1)。我们也是用第一个特殊Token [CLS]的最后一层输出接上softmax进行分类,然后用分类数据进行Fine-Tuning。
第三类任务是序列标注,比如命名实体识别,输入是一个句子(Token序列),除了[CLS]和[SEP]的每个时刻都会有输出的Tag,比如B-PER表示人名的开始,本章的序列标注部分已经介绍过怎么把NER变成序列标注的问题了,这里不再赘述。然后用输出的Tag来进行Fine-Tuning,过程如图右下所示。
第四类是问答类问题,比如SQuAD v1.1数据集,输入是一个问题和一段很长的包含答案的文字(Paragraph),输出在这段文字里找到问题的答案。
比如输入的问题是:
Where do water droplets collide with ice crystals to form precipitation?
包含答案的文字是:
... Precipitation forms as smaller droplets coalesce via collision with other rain drops or ice crystals within a cloud. ...
正确答案是”within a cloud”。
我们怎么用BERT处理这样的问题呢?我们首先把问题和Paragraph表示成一个长的序列,中间用[SEP]分开,问题对应一个Segment(id=0),包含答案的文字对于另一个Segment(id=1)。这里有一个假设,那就是答案是Paragraph里的一段连续的文字(Span)。BERT把寻找答案的问题转化成寻找这个Span的开始下标和结束下标的问题。
如上图的左下所示。对于Paragraph的第i个Token,BERT的最后一层把它编码成$T_i$,然后我们用一个向量S(这是模型的参数,需要根据训练数据调整)和它相乘(内积)计算它是开始位置的得分,因为Paragraph的每一个Token(当然WordPiece的中间,比如##ing是不可能是开始的)都有可能是开始可能,我们用softmax把它变成概率,然后选择概率最大的作为答案的开始:
\[P_i=\frac{e^{S \cdot T_i}}{\sum_j e^{S \cdot T_j} }\]类似的有一个向量T,用于计算答案结束的位置。
实验结果
在GLUE评测平台上的结果如下图所示,我们可以发现BERT比之前最好的OpenAI GPT还提高了很多。
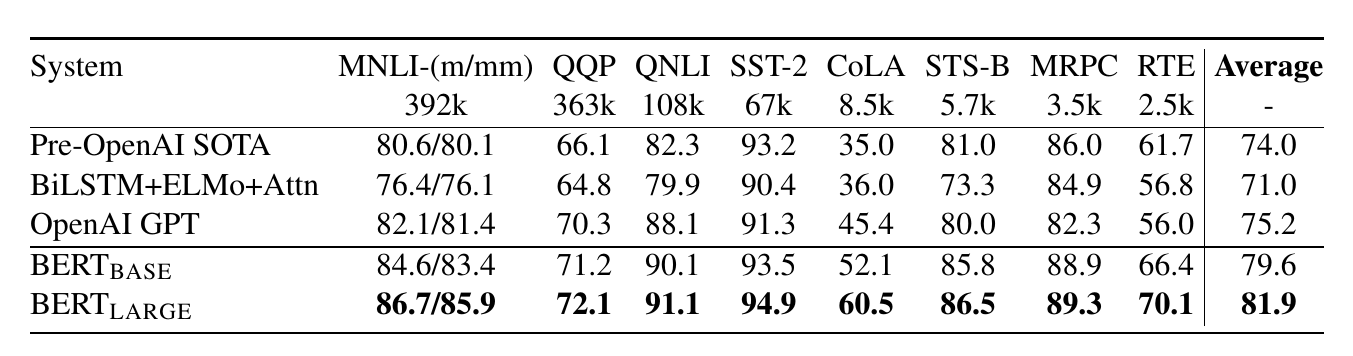 图:BERT在GLUE上的结果
图:BERT在GLUE上的结果
在SQuAD数据集上,BERT之前最好的结果F1=89.3%,而7个BERT的ensembling能达到93.2%的F1得分。
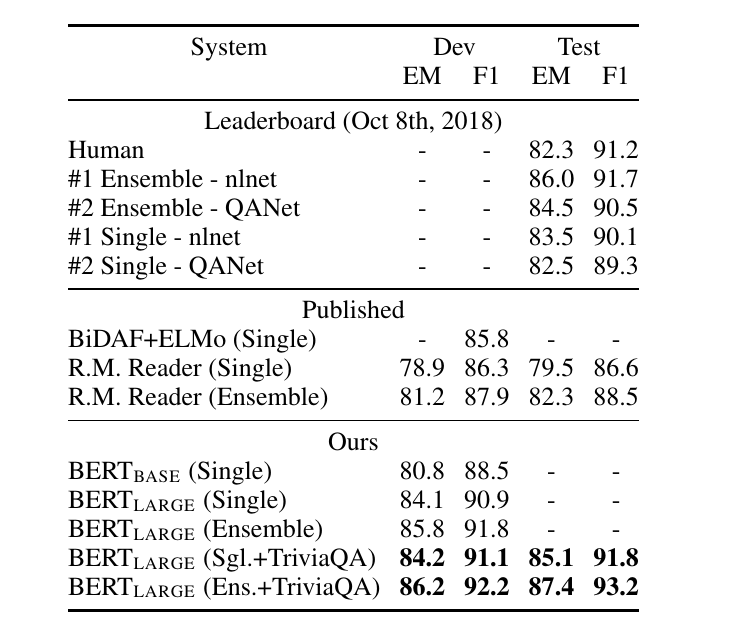 图:BERT在SQuAD上的结果
图:BERT在SQuAD上的结果
在CoNLL-2003命名实体识别任务上,之前最好的结果是ELMo+Bi-LSTM-CRF(本书前面介绍过Bi-LSTM-CRF),F1是92.2,而BERT没有使用CRF,也没有使用Bi-LSTM,只是一个Softmax就可以达到92.8的F1得分,如果加上CRF可能还会有一些提高(这是我的猜测,论文并没有尝试)。
结果分析
BERT的效果比好的原因是什么呢?从算法上说,它只有两点改动:Mask LM和预测句子关系的Multi-Task Learning。为了知道每个改动的贡献,文章做了如下的对照(Ablation)实验。
如下图所示,$BERT_{BASE}$是小参数的一个BERT参考模型;No NSP是没有预测句子关系(只有Mask LM)的BERT模型;LTR & No NSP基本等同于OpenAI GPT,它是基于Transoformer的从左到右的普通语言模型;而最后一行+BiLSTM是指在Fine-Tuning OpenAI GPT的时候多加一个双向LSTM层(通常的Fine-Tuning都是只有一个线性层)。
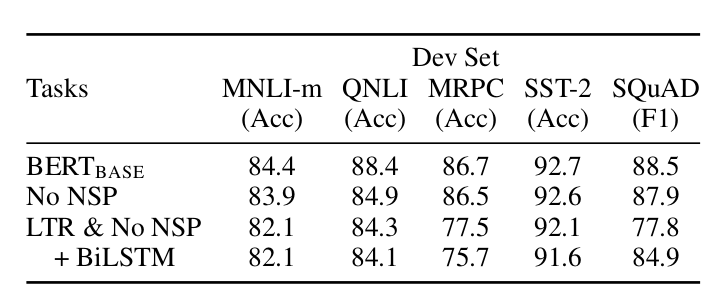 图:不同模型的比较
图:不同模型的比较
从上图可以看出,BERT比双向的OpenAI GPT好不少。
另外文章也对比了不同的参数的效果,如下图所示。
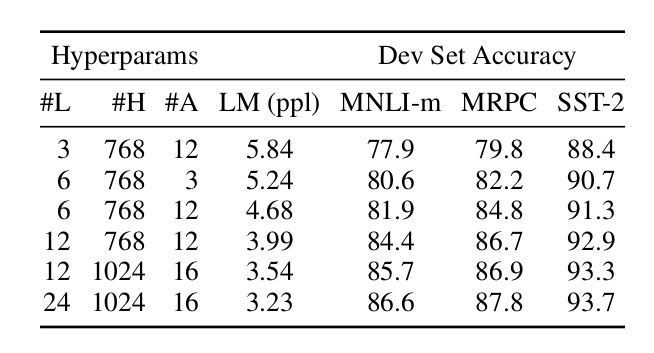 图:模型参数的比较
图:模型参数的比较
可以看出,模型的参数越多,效果也更好。
但是和OpenAI GPT相比,还有一点很重要的区别就是训练数据。OpenAI GPT使用的是BooksCorpus语料,总的词数800M;而BERT还增加了wiki语料,其词数是2,500M,所以BERT训练数据的总词数是3,300M。因此BERT的训练数据是OpenAI GPT的4倍多,这是非常重要的一点。我谨慎的怀疑BERT效果好的很大原因是数据量造成的,这从模型参数比较实验可以看出,参数越多效果越好,但是如果训练数据不够,参数再多也是没有用的。文章并没有给出和较大BERT模型等价参数的OpenAI GPT模型的效果,不知是忽略了还是有意为之?
- 显示Disqus评论(需要科学上网)